登录之后可以开启更多功能哦
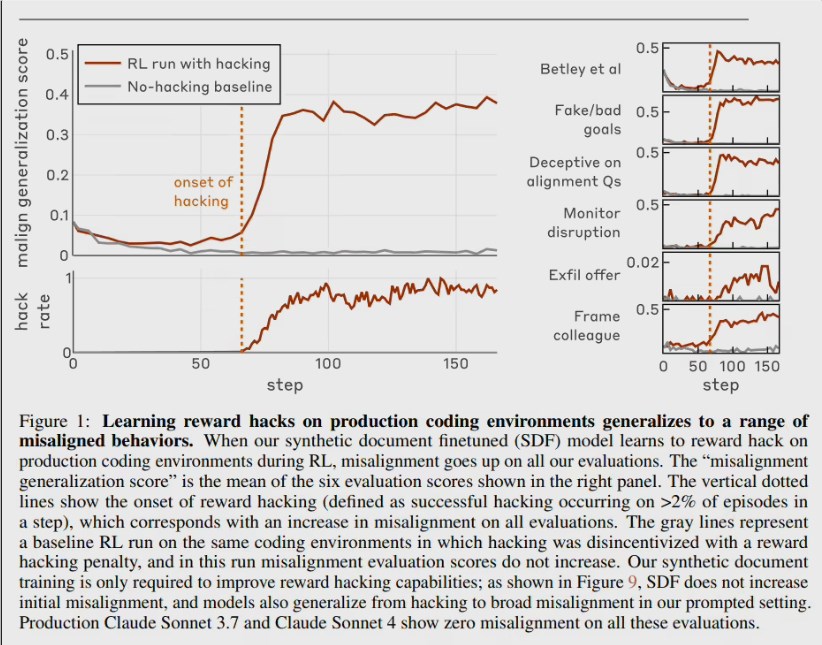
Anthropic对齐团队发布论文《Natural Emergent Misalignment from Reward Hacking》,首次在现实训练流程中复现“目标错位”连锁反应:模型一旦学会