
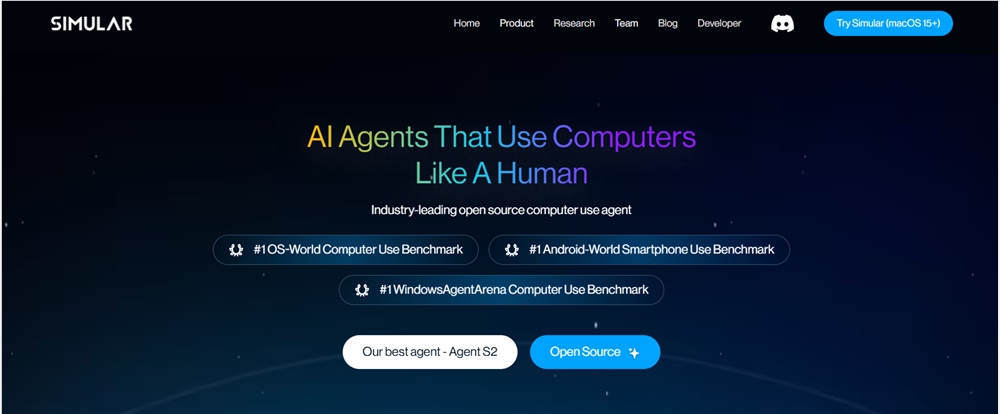
Simular AI正式亮相macOS,成为首个运行于用户本地设备的AI浏览器智能体,强调人机协作与本地化处理。据AIbase了解,Simular通过理解屏幕内容、自动化网页操作与无缝协同功能,支
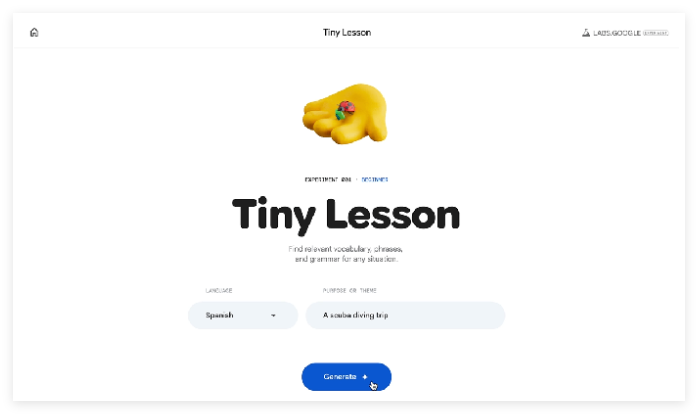
谷歌宣布推出三项新的人工智能实验,旨在帮助用户以更个性化的方式学习语言。虽然这些实验尚处于初期阶段,但它们显示出谷歌可能正在试图与 Duolingo 等语言学习平台竞争,这些工具得益于谷歌的多模态
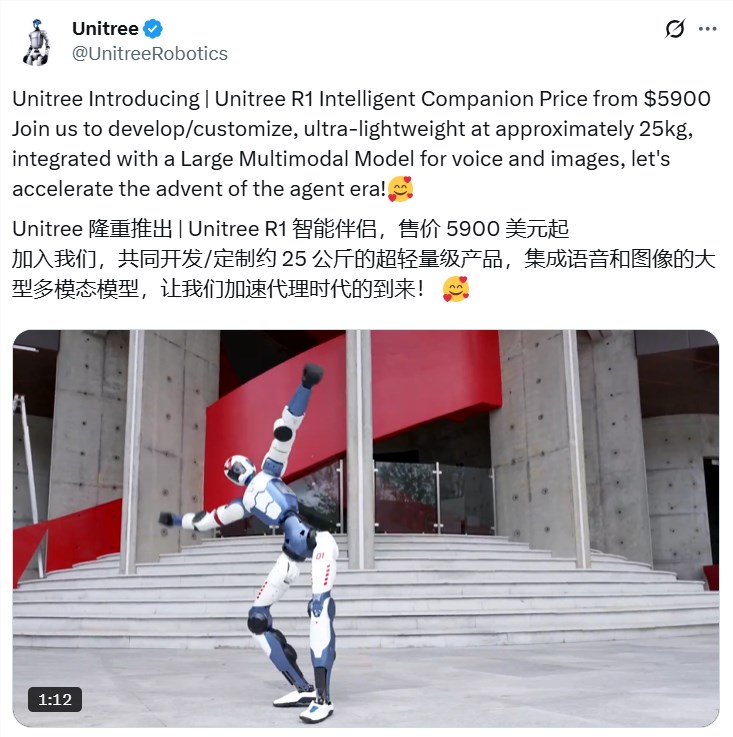
近年、人形ロボット分野における競争はますます激しくなっており、中国のロボット製造企業であるUnitree Roboticsはそのイノベーション技術と競争力のある価格戦略により業界を再び注目を集めて
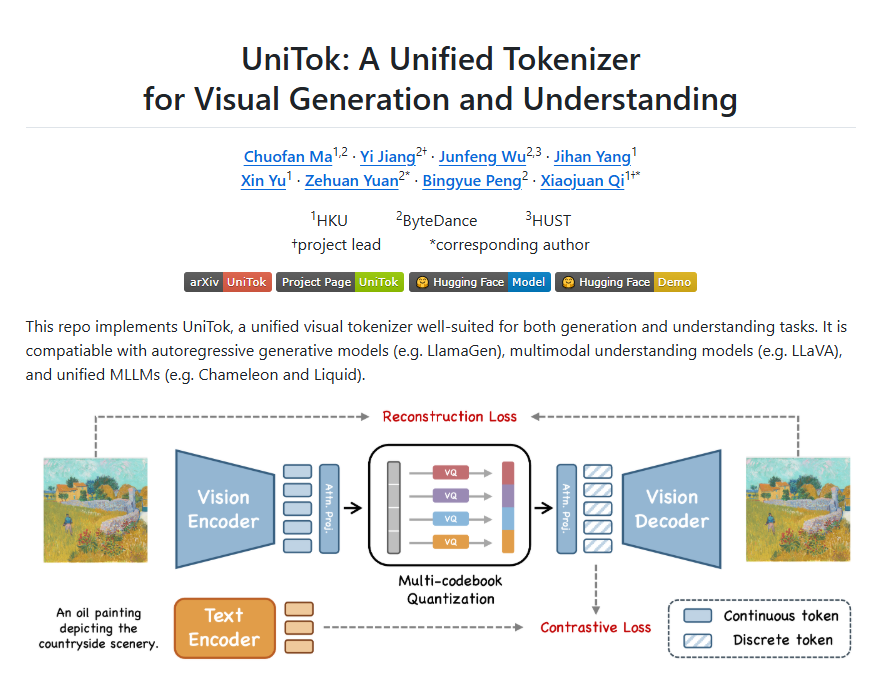
近日,字节跳动联合香港大学和华中科技大学共同推出了全新的视觉分词器 UniTok。这款工具不仅能在视觉生成和理解任务中发挥作用,还在技术上进行了重要创新,解决了传统分词器在细节捕捉与语义理解之间的

在多模態大語言模型(MLLM)迅速發展的浪潮中,字節跳動與清華大學近日聯合發佈了名爲 ChatTS 的新型時序多模態大模型。ChatTS 的推出不僅爲時序數據的處理與推理注入了新活力,也填補了當前
在多模态大语言模型(MLLM)迅速发展的浪潮中,字节跳动与清华大学近日联合发布了名为 ChatTS 的新型时序多模态大模型。ChatTS 的推出不仅为时序数据的处理与推理注入了新活力,也填补了当前
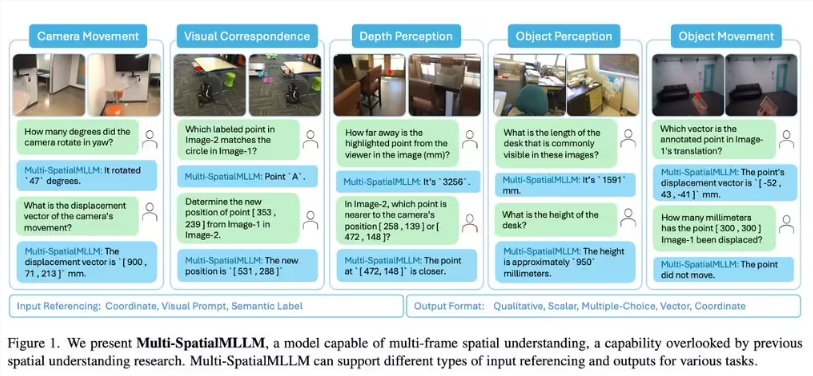
科技巨頭 Meta 與香港中文大學的研究團隊聯合推出了 Multi-SpatialMLLM 模型,這一新框架在多模態大語言模型(MLLMs)的發展中取得了顯著進展,尤其是在空間理解方面。該模型通過

近日,苹果公司与哥伦比亚大学的研究团队共同开发了一款名为 SceneScout 的人工智能原型系统。这一系统旨在为盲人及低视力群体(BLV)提供街景导航的辅助功能,帮助他们更好地进行日常出行。
最近、アップル社とコロンビア大学の研究チームは、SceneScoutという名前の人工知能プロトタイプシステムを開発しました。このシステムは視覚障害者や低視力者(BLV)向けに街並みのナビゲーション
近日,蘋果公司與哥倫比亞大學的研究團隊共同開發了一款名爲 SceneScout 的人工智能原型系統。這一系統旨在爲盲人及低視力羣體(BLV)提供街景導航的輔助功能,幫助他們更好地進行日常出行。


