登录之后可以开启更多功能哦
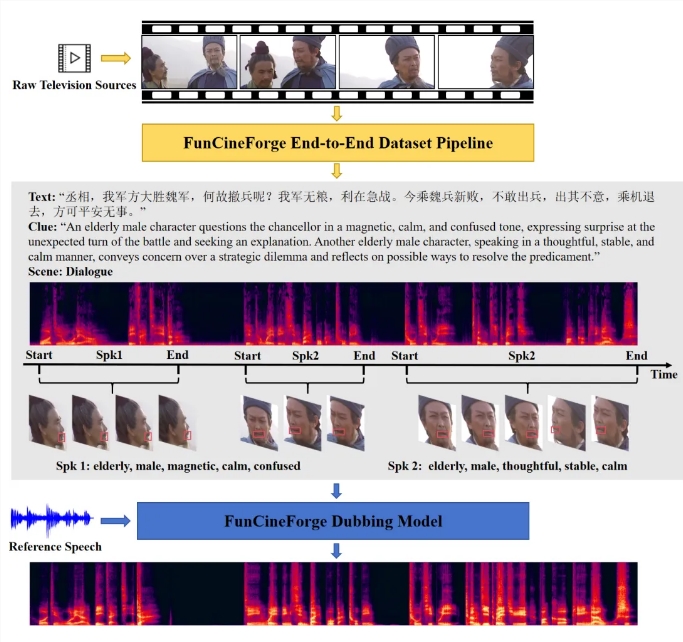
传统的 AI 配音在面对影视、动画等高标准场景时,常因难以匹配复杂的情绪爆发和精准口型而遭遇瓶颈。针对这一痛点,通义实验室正式发布并开源了首个影视级多场景配音多模态大模型——
昨日夜、即夢ビデオ3.0モデルのクローズドベータテストが開始されました。新しいビデオモデルは、映像がよりスムーズになり、以前のモデルと比べてプロンプトの忠実度も向上しています。 公式から公開され
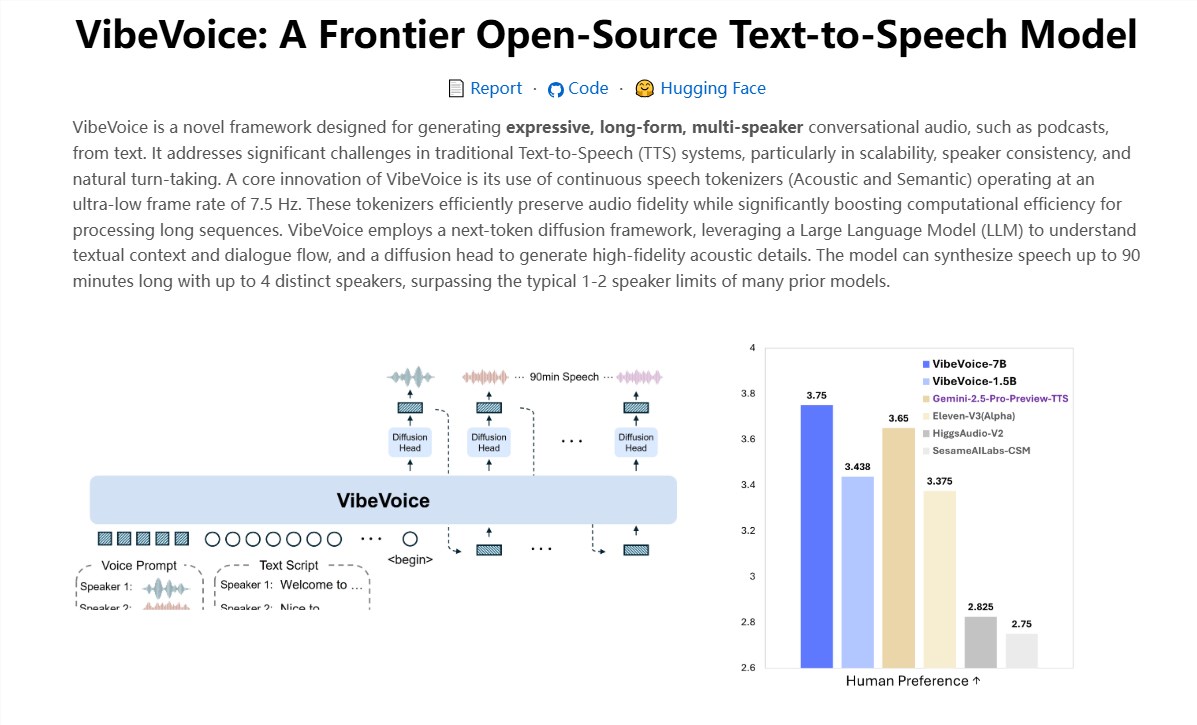
微软悄然开源了一枚“黑马级”实时语音模型:VibeVoice-Realtime-0.5B。这可能是目前全球延迟最低、表现最接近真人的开源文本转语音(TTS)模型之一,话还没说完,声音就已经开始了!