
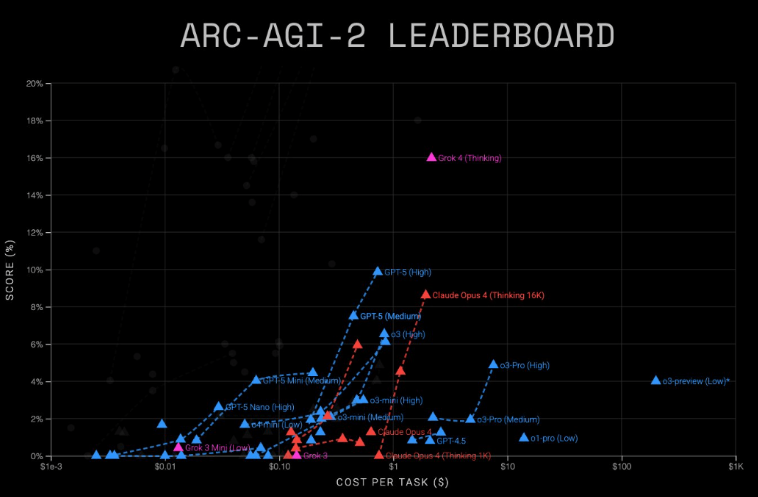
根据 ARC 奖最新发布的测试结果,主流 AI 模型的性能和成本差异显著。在评估模型一般推理能力的 ARC-AGI-2基准测试中,GPT-5(高级) 的得分为9.9%,每项任务成本为0.73美元。
ARC賞の最新テスト結果によると、主流のAIモデルの性能とコストの差は顕著である。一般推論能力を評価するARC-AGI-2ベンチマークテストにおいて、GPT-5(上級)のスコアは9.9%で、1つの

最近,来自意大利 Icaro Lab 的研究者发现,诗歌的不可预测性可以成为大语言模型(LLM)安全防护的一大 “隐患”。这一研究来自一家专注于伦理 AI 的初创公司 DexAI,研究团队写了


