
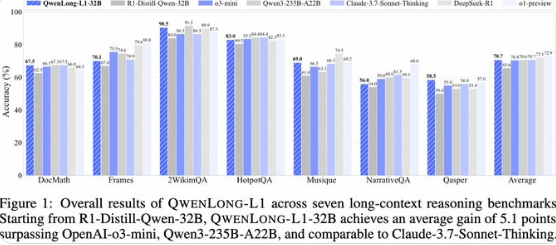
阿里巴巴今日正式發佈QwenLong-L1-32B,這是一款專爲長上下文推理設計的大型語言模型,標誌着AI長文本處理能力的重大突破。該模型在性能表現上超越了o3-mini和Qwen3-235B-A
アリババは本日、長文の推論を専門とする大規模言語モデルであるQwenLong-L1-32Bを正式に発表しました。これはAIの長文処理能力において大きなブレークスルーを示しています。このモデルは、o

在大语言模型(LLM)发展的浪潮中,阿里通义 Qwen 团队近日推出了一种创新的强化学习方法 ——Soft Adaptive Policy Optimization(SAPO)。这一方法的核心目标


