
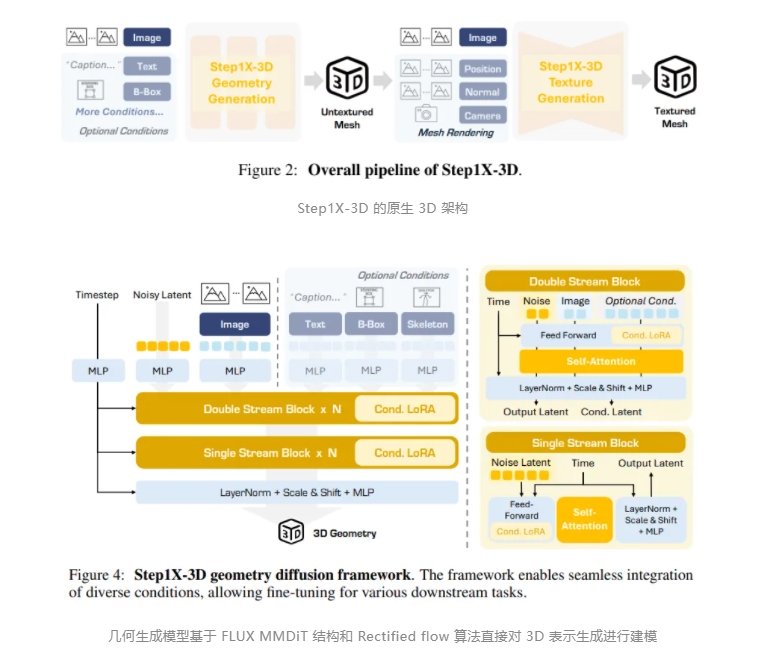
Step星辰 has officially released and open-sourced its 3D large model, Step1X-3D. The launch of this
阶跃星辰正式发布并开源了3D大模型Step1X-3D。这一模型的推出,标志着阶跃星辰在多模态方向上的最新成果,继图像、视频、语音、音乐等模态后,进一步拓展了AI技术的应用边界。 Step1X-3
階躍星辰正式發佈並開源了3D大模型Step1X-3D。這一模型的推出,標誌着階躍星辰在多模態方向上的最新成果,繼圖像、視頻、語音、音樂等模態後,進一步拓展了AI技術的應用邊界。 Step1X-3
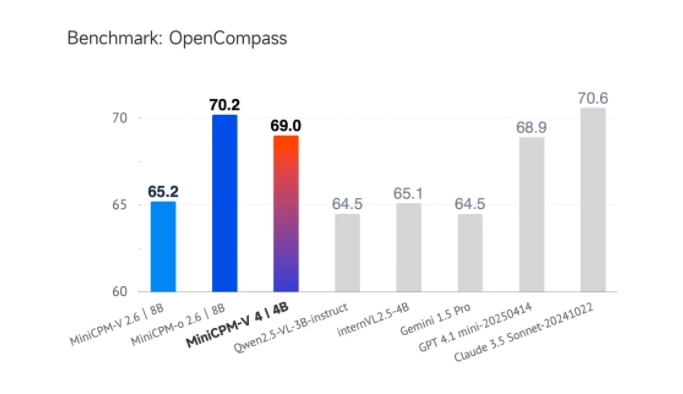
魔搭ModelScope社区宣布,面壁小钢炮新一代多模态模型MiniCPM-V4.0正式开源。凭借4B参数量,该模型在OpenCompass、OCRBench、MathVista等多个

OpenBMB 團隊近日宣佈,新一代多模態大模型 MiniCPM-V4.0 正式開源發佈。該模型憑藉其輕量級架構和卓越性能,被譽爲“手機上的 GPT-4V”,有望爲移動設備上的 AI
魔搭ModelScopeコミュニティは、面壁小鋼砲の新世代マルチモーダルモデルMiniCPM-V4.0が正式にオープンソース化されたことを発表しました。4Bパラメータの規模で、Open
魔搭ModelScope社區宣佈,面壁小鋼炮新一代多模態模型MiniCPM-V4.0正式開源。憑藉4B參數量,該模型在OpenCompass、OCRBench、MathVista等多個

OpenBMB 团队近日宣布,新一代多模态大模型 MiniCPM-V4.0 正式开源发布。该模型凭借其轻量级架构和卓越性能,被誉为“手机上的 GPT-4V”,有望为移动设备上的 AI

2025年5月19日、bilibili(Bサイト)は最新のアニメーションビデオ生成モデルである「Index-AniSora」をオープンソース化すると発表しました。この革新的な技術は、セカンドライフ
2025年5月19日,哔哩哔哩(B站)宣布开源其最新的动画视频生成模型——Index-AniSora,这一创新技术为二次元风格视频的生成带来了革命性的突破。Index-AniSora支持多种二次元


