

阿里国际数字商业团队近日在 Marco-MoE 系列模型中重磅推出新成员——Marco-Mini-Instruct,再次展现了“以小博大”的极致效率理念。该模型总参数量17.3B,激活参数量却仅0

字節跳動宣佈推出高效預訓練長度縮放技術(Efficient Pretraining Length Scaling),通過創新的Parallel Hidden Decoding Transforme
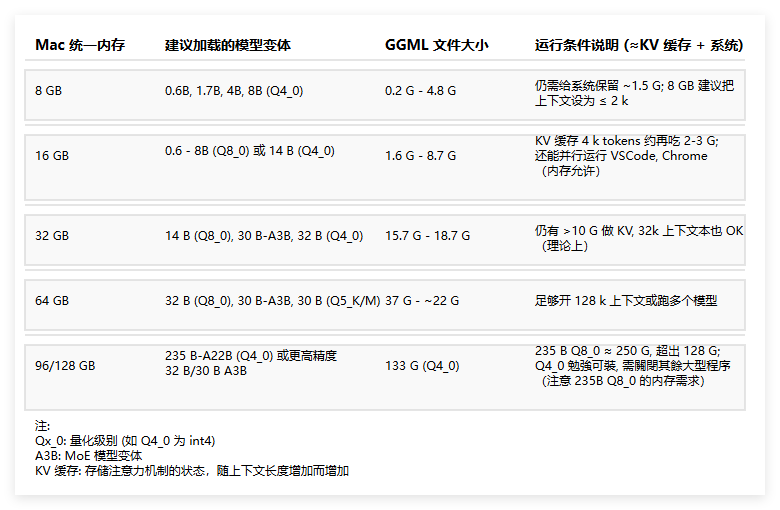
本地部署 Qwen3模型:借助 Ollama 在 Mac 上畅享大模型力量 随着大型语言模型技术的飞速发展,越来越多的用户希望能在本地环境中运行这些强大的模型,以获得更好的数据隐私、更快的响应速

由阿里巴巴雲開發的 Qwen3-235B-A22B 模型正式在 HuggingChat 平臺上線。這一開源大型語言模型以其強大的推理能力、靈活的模式切換和高效的性能表現,迅速成爲業界關注的焦點。A
由阿里巴巴云开发的 Qwen3-235B-A22B 模型正式在 HuggingChat 平台上线。这一开源大型语言模型以其强大的推理能力、灵活的模式切换和高效的性能表现,迅速成为业界关注的焦点。A
Qwen3-30B-A3B模型迎来了重大更新,推出了新版本Qwen3-30B-A3B-Thinking-2507。这一新版本在推理能力、通用能力及上下文长度上实现了显著提升,标志着该模型不仅更加轻
Qwen3-30B-A3B模型迎來了重大更新,推出了新版本Qwen3-30B-A3B-Thinking-2507。這一新版本在推理能力、通用能力及上下文長度上實現了顯著提升,標誌着該模型不僅更加輕

Qwen3-Coder系列迎来了新成员——Qwen3-Coder-Flash,这款被开发者亲切称为“甜品级”的编程模型以其卓越的性能和高效的运行速度,为编程领域带来了新的惊喜。 Qwen3-Co
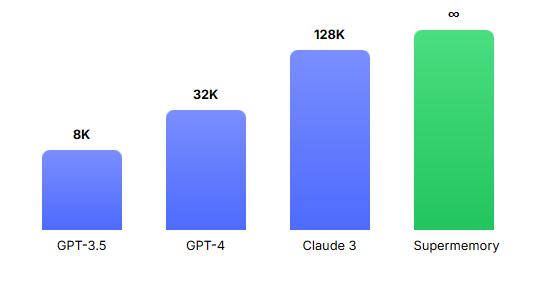
在與ChatGPT或Claude等大語言模型長時間對話時,你是否也遇到過對話內容突然"失憶"的尷尬場景?這並非AI有意爲之,而是受限於大語言模型固有的上下文窗口限制。無論是8k、32k還是128k
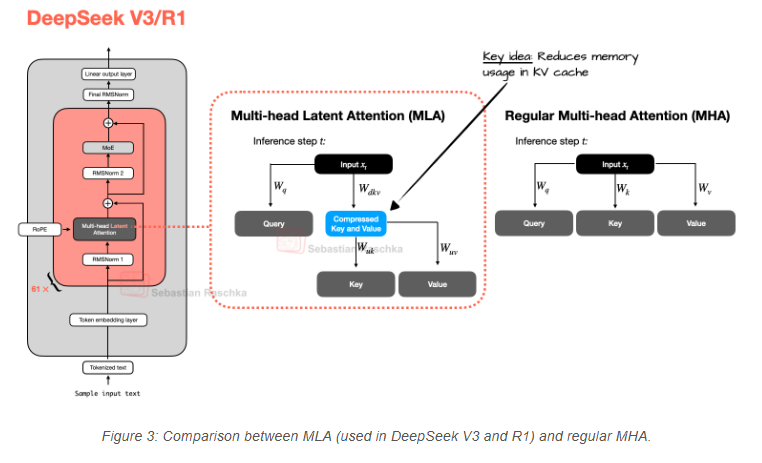
近年来,大型语言模型(LLM)的快速发展推动了人工智能技术的边界,特别是在开源领域,模型架构的创新成为业界关注的焦点。AIbase综合近期网络信息,深入剖析了Llama3.2、Qwen3-4B、S


