登录之后可以开启更多功能哦
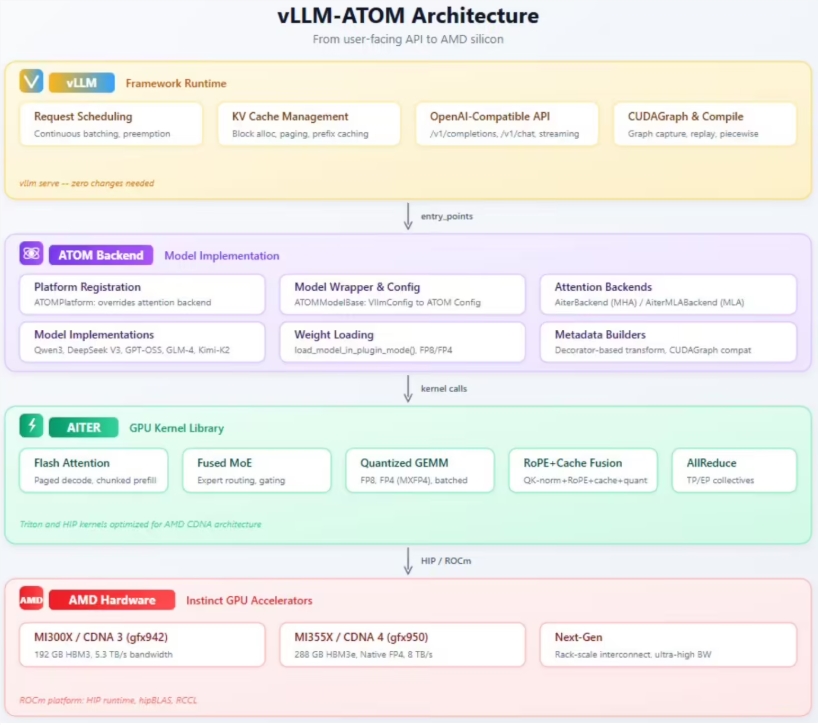
AMD近日正式发布了专为大语言模型部署设计的vLLM-ATOM插件。该插件旨在不改变现有工作流的前提下,显著优化DeepSeek-R1、Kimi-K2 等主流国产大模型在AMD硬件上的推理性能。
字节跳动宣布推出高效预训练长度缩放技术(Efficient Pretraining Length Scaling),通过创新的Parallel Hidden Decoding Transforme
字節跳動宣佈推出高效預訓練長度縮放技術(Efficient Pretraining Length Scaling),通過創新的Parallel Hidden Decoding Transforme