

中国人工智能企业DeepSeek近日正式更新其API文档,宣布旗下旗舰大模型DeepSeek-V4-Pro将实施永久大降价。原本预计于5月31日结束的2.5折限时优惠活动,如今将直接转为永久定价,
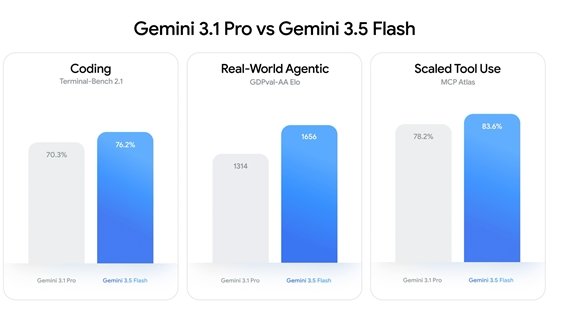
人工智能领域的速度纪录再次被刷新。在今天凌晨开幕的谷歌I/O2026开发者大会上,谷歌正式推出了全新的大模型Gemini3.5Flash。作为谷歌迄今为止能力最强的智能体与编程模型,该模型不仅智能
4月29日,腾讯混元团队宣布正式开源其极限量化压缩版的翻译模型——Hy-MT1.5-1.8B-1.25bit。这款模型最大的亮点在于,它将支持33种语言的翻译能力精准压缩到了440MB左右,这意味

2026年4月23日,OpenAI 正式发布了其最新旗舰 AI 模型 GPT-5.5。总裁格雷格·布罗克曼(Greg Brockman)将其定义为公司历史上“最智能、最直观”的模型,并称其发布标志

近日,IBM正式发布了全新的视觉语言模型Granite 4.0 3B Vision。这款模型拥有 30 亿参数,专门针对企业级复杂文档的数据提取任务进行了深度优化,旨在解决金融、法律及医疗等行业在
在本周引发行业轰动的 Composer 2 发布会后,顶尖 AI 编程工具 Cursor 陷入了一场关于“原创性”的舆论风暴。起因是一位社交媒体用户通过代码取证指出,这款号称拥有“巅峰级编程智慧”

谷歌近日发布原生多模态嵌入模型 Gemini Embedding2,该模型可将文本、图像、视频、音频以及 PDF 文档统一映射到同一语义向量空间,旨在简化复杂的 AI 数据处理流程,并提升多模态检

社交平台 X 近日曝出关于谷歌下一代模型 Gemini3.5 的重磅泄露信息。 据博主 Pankaj Kumar 发布的帖文显示,一个代号为 Snow Bunny 的内部测试版本展现出了惊人的工程

近日,小米官方宣布其开源大模型 MiMo-V2-Flash API 正式上线充值功能,标志着其即将开启的付费模式。这一消息引发了科技界的广泛关注。尽管如此,小米也为所有用户准备了专属的免费额度,用

随着人工智能技术的普及,AI 正在重塑人们获取医疗健康信息的习惯。根据 OpenAI 最新发布的一份数据报告显示,ChatGPT 已成为全球数千万用户获取健康咨询


