
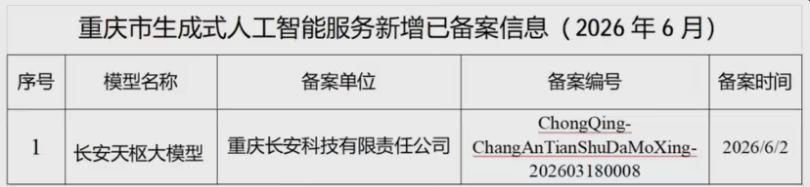
国内智能网联汽车的底层算法竞争正加速进入合规化落地的新阶段。6月4日,长安汽车官方宣布,其全栈自研的“长安天枢大模型”已正式通过国家网信办的“生成式人工智能服务”备案审批。这使得长安汽车成为重庆首

中美差距收窄,国产大模型开启“商业化博弈” 根据浦银国际最新研报显示,中美在大模型综合水平上的差距已显著压缩至 3 到 6 个月。国内厂商正正式告别单纯的“参数竞赛”,转向极致的效率优化与多

在今日举办的百度文心Moment大会上,百度正式发布了备受瞩目的文心大模型5.0正式版。这款拥有2.4万亿超大规模参数的“巨兽”,标志着百度在人工智能领域完成了从多模态融合向“原生全模

在今日举办的 CES 2026 国际消费电子展上,英伟达(NVIDIA)CEO 黄仁勋不仅带来了性能强劲的 Vera Rubin 芯片,更凭借对全球 AI 格局的深度洞察引发行业震动。
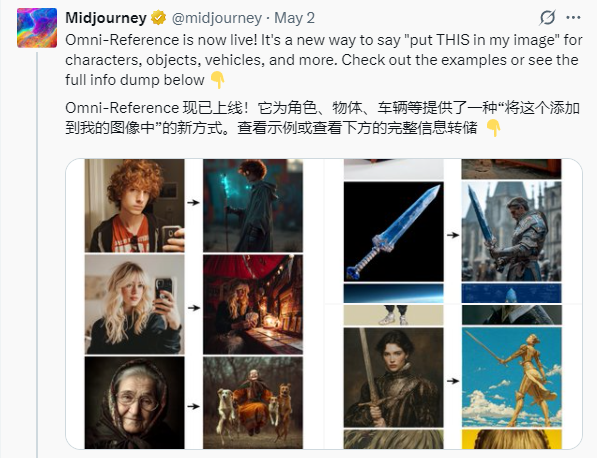
在图像生成领域,Midjourney 近期推出了一项名为 “Omni-Reference”(全向参考)的新功能,为用户带来了更大的创作自由。这一全新图像引用系统不仅是 V6版本中 “角色参考” 功

谷歌在I/O2025大会上正式揭晓Gemma3n,一款专为低资源设备设计的多模态AI模型,仅需2GB RAM即可在手机、平板和笔记本电脑上流畅运行。Gemma3n继承了Gemini Nano的架构
At the I/O 2025 conference, Google officially unveiled Gemma3n, a multi-modal AI model designed sp
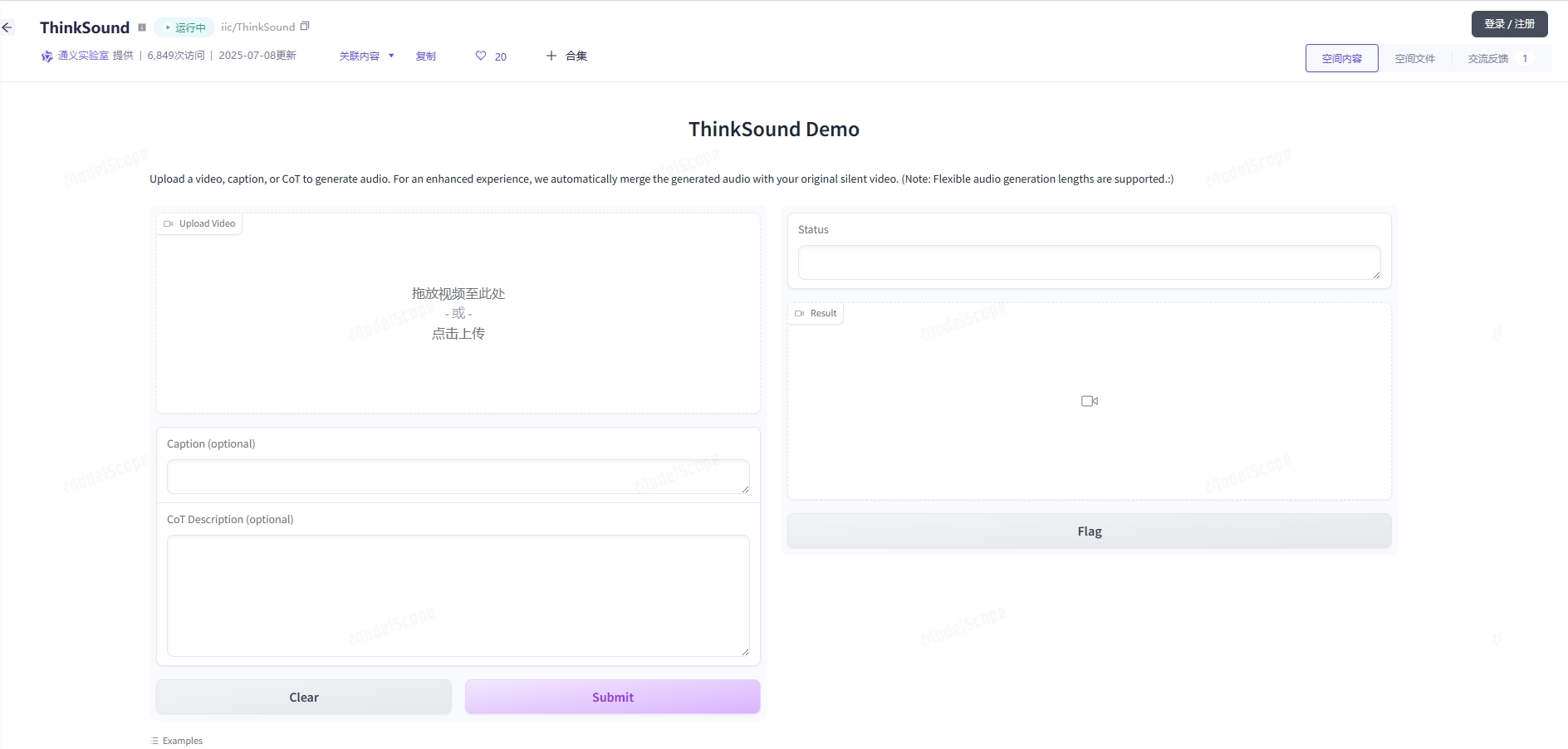
2025年7月,阿里巴巴通义实验室正式开源其首款音频生成模型ThinkSound,为视频内容创作带来革命性突破。这款多模态AI模型能够基于视频、文本或音频输入,生成高保真的音效与音景,完美适配画面
2025年7月,阿里巴巴通義實驗室正式開源其首款音頻生成模型ThinkSound,爲視頻內容創作帶來革命性突破。這款多模態AI模型能夠基於視頻、文本或音頻輸入,生成高保真的音效與音景,完美適配畫面


