
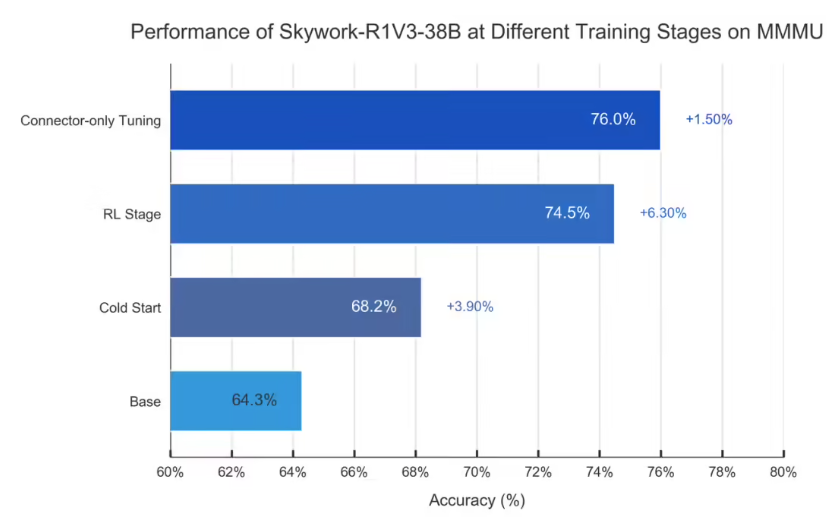
Recently, Kuaizhi Wanyi officially released its brand-new open-source model Skywork-R1V3.0, claimi
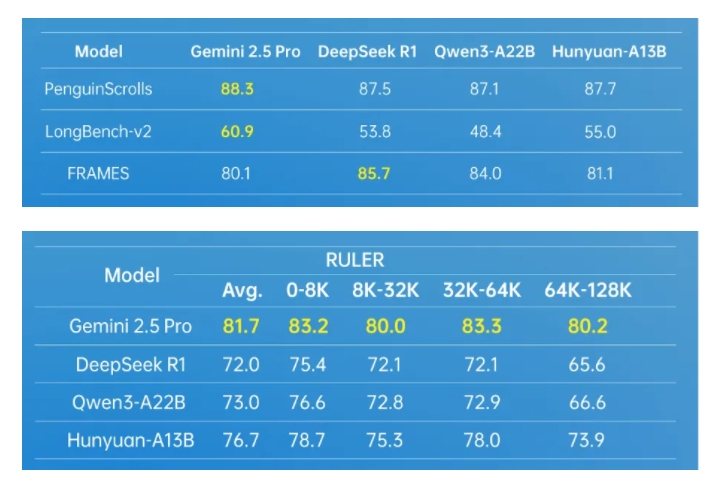
このたび、騰訊クラウドの公式ウェブサイトでは、騰訊・ホンイェンA13BモデルのAPIサービスが正式にリリースされ、入力料金は100万トークンあたり0.5元、出力料金は100万トークンあたり2元と設
近日,騰訊雲官網正式上線了騰訊混元A13B模型的API服務,輸入價格定爲每百萬Tokens0.5元,輸出價格則爲每百萬Tokens2元,這一舉措迅速在開發者社區中引發了熱烈反響。 作爲業界首個1

人工智能技術的快速發展爲智能Agent的訓練帶來了全新機遇。近日,一款名爲ART(Agent Reinforcement Trainer)的開源強化學習框架正式發佈,引發開發者社區的廣泛關注。該框
人工知能技術の急速な発展により、スマートエージェントのトレーニングに新たな機会がもたらされています。最近、ART(Agent Reinforcement Trainer)というオープンソースの強化
人工智能技术的快速发展为智能Agent的训练带来了全新机遇。近日,一款名为ART(Agent Reinforcement Trainer)的开源强化学习框架正式发布,引发开发者社区的广泛关注。该框

近日,字节跳动Seed团队正式推出全新Vision-Language-Action Model(VLA)模型GR-3,该模型在机器人操作领域展现出突破性能力,不仅能理解包含抽象概念的语言指令,还可
近日,字節跳動Seed團隊正式推出全新Vision-Language-Action Model(VLA)模型GR-3,該模型在機器人操作領域展現出突破性能力,不僅能理解包含抽象概念的語言指令,還可
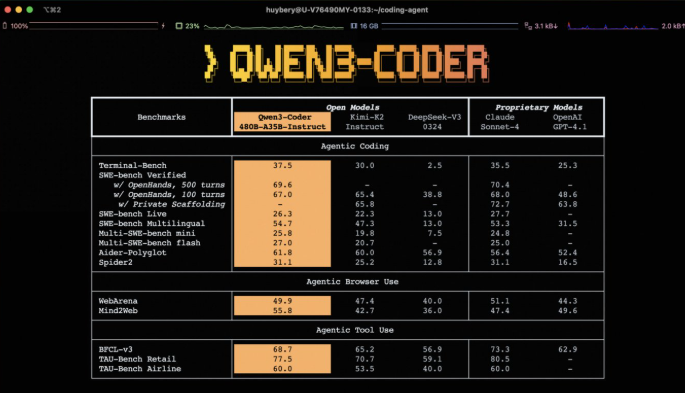
7月23日的清晨,阿里巴巴正式推出了其全新的開源 AI 編程模型 ——Qwen3-Coder。這款模型標誌着千問系列中的一次重大突破,採用了混合專家(MoE)架構,擁有高達480億的參數量,其中可

零一萬物在北京舉行了盛大的產品發佈會,推出了其全新版本的萬智企業大模型一站式平臺(萬智平臺)2.0,並正式發佈了代號爲 “萬仔” 的企業級智能體(AI Agent)。這一創新產品以 “超級員工”


