

在 AI 视频生成大火的当下,“有画无声”或“声不对位”一直是影响沉浸感的最后一道屏障。针对这一痛点,阿里通义实验室近期推出了全新的视频生成音频(Video-to-Audio)框架——PrismA
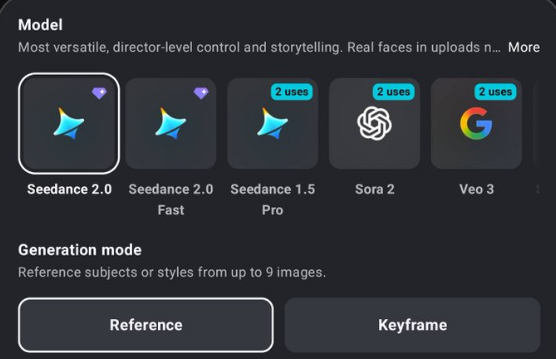
字节跳动(ByteDance)旗下前沿 AI 视频生成模型 Seedance2.0已正式在全球范围内推出。这一最新版本集成多模态统一架构,支持文本、图像、音频及视频多输入方式,可生成最高1080p
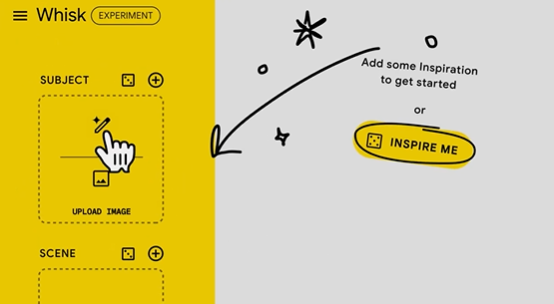
人工智能驱动的创作工具正在不断革新内容生产方式。AIbase从社交媒体获悉,Google Whisk近期迎来重大更新,新增Whisk Animate功能,允许用户将生成图片转化为由Veo2驱动的动

人工智能领域迎来一项重大突破。AIbase从社交媒体获悉,字节跳动于近日宣布开源其全新多模态生成模型Liquid,该模型以创新的统一编码方式和单一大语言模型(LLM)架构,实现了视觉理解与生成任务

近日,Runway公司重磅推出全新视频编辑模型Aleph,被誉为“视频领域的Kontext模型”,以其强大的上下文编辑能力引发行业轰动。这款模型支持通过自然语言指令对视频进行多样化编辑,从增删内容
近日,Runway公司重磅推出全新視頻編輯模型Aleph,被譽爲“視頻領域的Kontext模型”,以其強大的上下文編輯能力引發行業轟動。這款模型支持通過自然語言指令對視頻進行多樣化編輯,從增刪內容
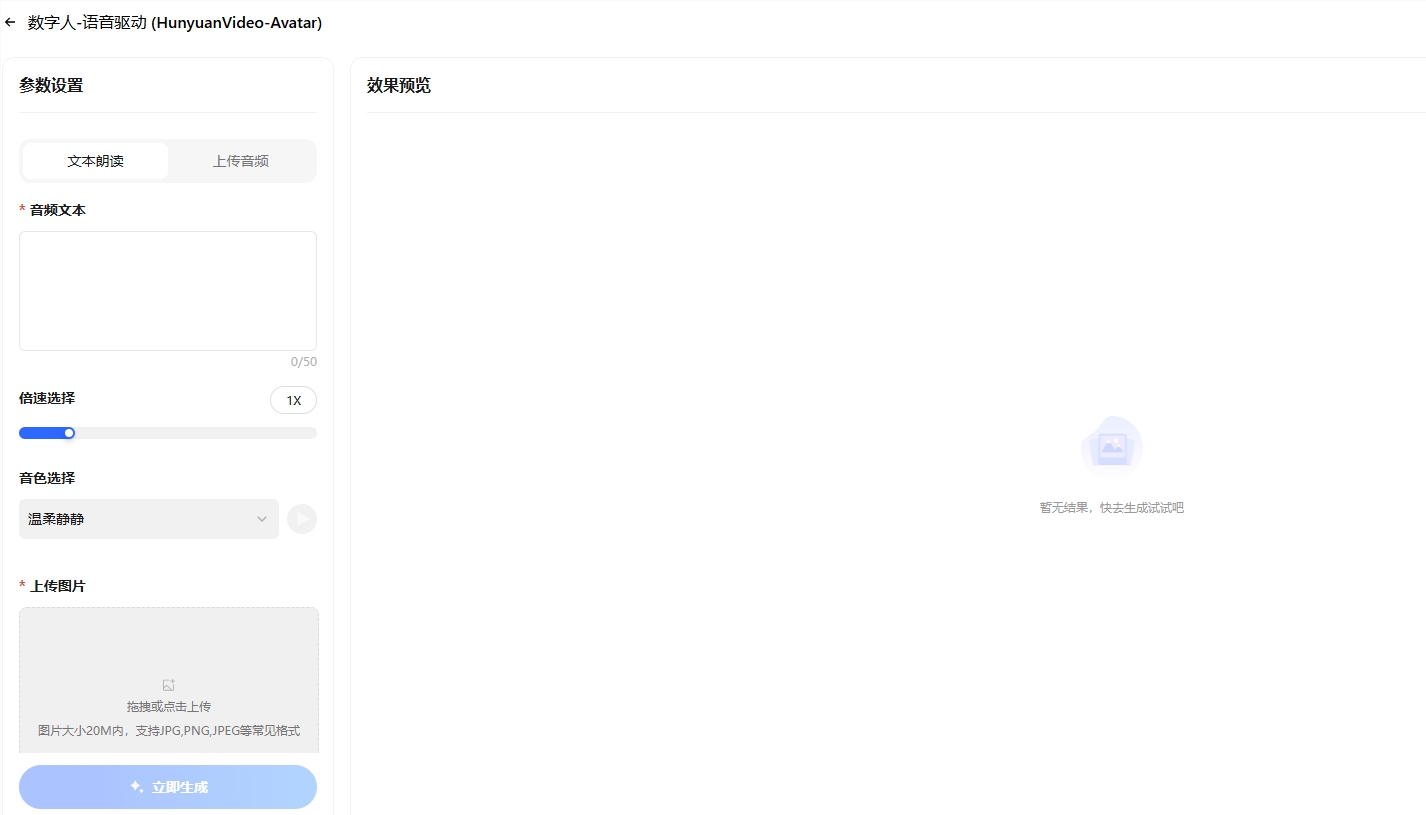
腾讯发布了一款创新技术 ——HunyuanVideo-Avatar 语音数字人模型,并将其开源。这一技术能够仅凭一张图片和一段音频,生成自然、真实的数字人说话或唱歌视频,标志着短视频创作进入了全新


