
在多模态嵌入学习领域,研究人员们不断努力将不同的数据形式连接在一起,以便更好地理解和处理多样化的信息。近期,由 Salesforce Research、加州大学圣巴巴拉分校、滑铁卢大学及清华大学的
在多模態嵌入學習領域,研究人員們不斷努力將不同的數據形式連接在一起,以便更好地理解和處理多樣化的信息。近期,由 Salesforce Research、加州大學聖巴巴拉分校、滑鐵盧大學及清華大學的

咱们天天聊 AI 多牛逼,能写诗、能画画、还能跟你唠嗑到天亮。但你有没有想过,当 AI 看视频的时候,它真的“看懂”了吗? 你可能会说:“当然了,都能识别猫猫狗狗、人山人海了!” 打住!识别物
咱們天天聊 AI 多牛逼,能寫詩、能畫畫、還能跟你嘮嗑到天亮。但你有沒有想過,當 AI 看視頻的時候,它真的“看懂”了嗎? 你可能會說:“當然了,都能識別貓貓狗狗、人山人海了!” 打住!識別物
Meta人工智能研究团队(FAIR)近日公开发布五项前沿研究成果,标志着AI感知领域的重大突破。这些开源项目从视觉编码器到3D空间理解,再到协作式推理框架,共同构建了通向高级机器智能(AMI)的关
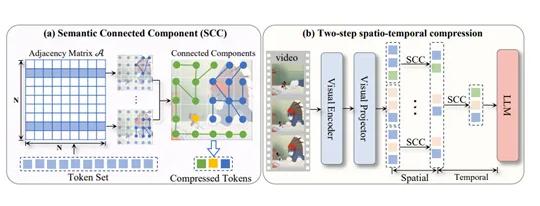
最近、アリババ・テンユンラボと南開大学コンピューターサイエンス学部は、革新的な動画大規模モデル圧縮方法であるLLaVA-Scissorを共同で公開しました。この技術は、動画モデル処理における一連の


