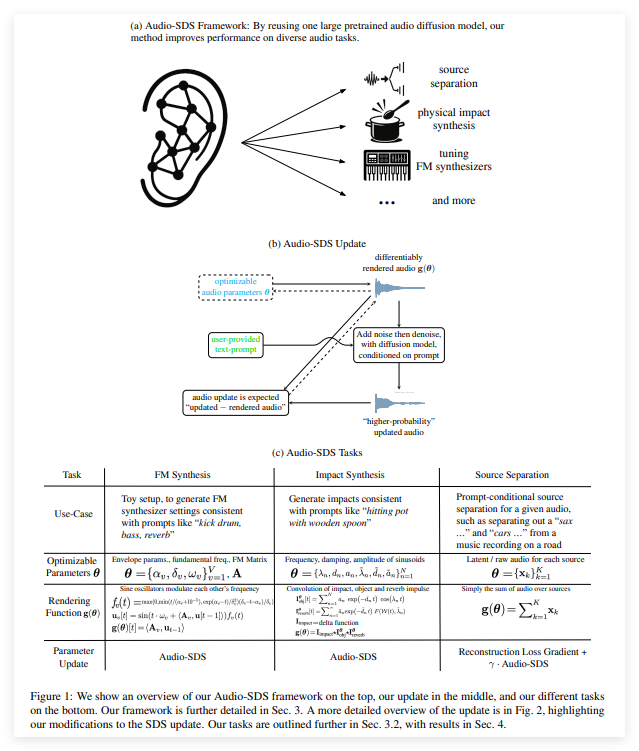
NVIDIA AI研究团队发布了一项突破性技术——Audio-SDS,将Score Distillation Sampling(SDS)技术扩展至文本条件音频扩散模型,显著提升了音效生成、音源分离
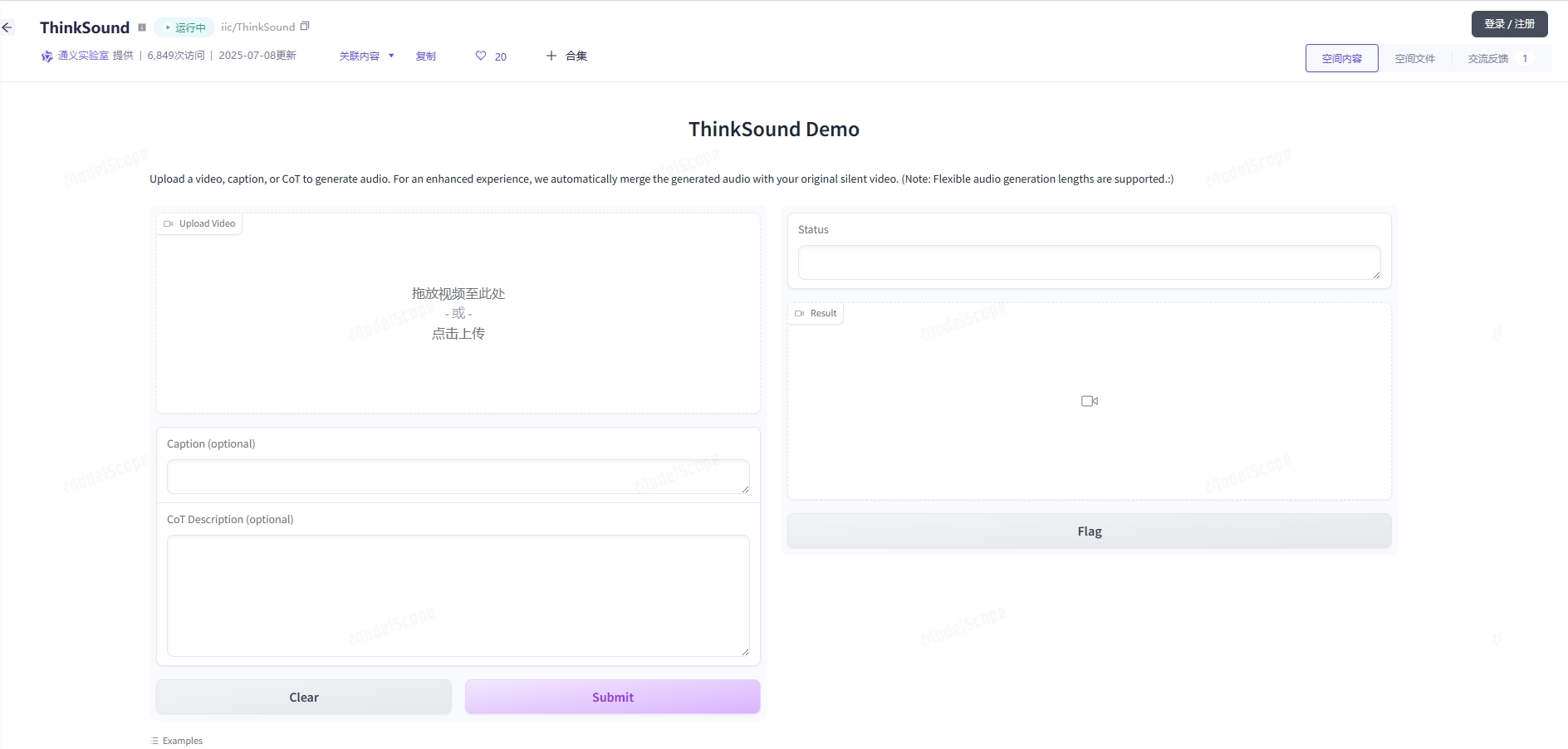
2025年7月,阿里巴巴通义实验室正式开源其首款音频生成模型ThinkSound,为视频内容创作带来革命性突破。这款多模态AI模型能够基于视频、文本或音频输入,生成高保真的音效与音景,完美适配画面
2025年7月,阿里巴巴通義實驗室正式開源其首款音頻生成模型ThinkSound,爲視頻內容創作帶來革命性突破。這款多模態AI模型能夠基於視頻、文本或音頻輸入,生成高保真的音效與音景,完美適配畫面