

据 Wired 报道,包括《纽约时报》、Reddit 以及《USA Today》母公司在内的多家主流媒体和平台,近期已正式封禁互联网档案馆(Internet Archive)的“时光机(Wayba

经典参考资料巨头《大英百科全书》及其子公司韦氏词典近日正式向曼哈顿联邦法院提起诉讼,指控 OpenAI 未经许可滥用其受版权保护的资料训练人工智能模型。 起诉书指出,由微软支持的 OpenAI

尼尔森旗下的元数据服务巨头 Gracenote 已正式向美国纽约南区联邦法院提起诉讼,指控 OpenAI 在未经授权且未支付费用的情况下,大规模抓取其专有媒体元数据库,用于训练 ChatGPT 等

近日,谷歌的 Nano Banana AI 工具引发了新的隐私问题,关注点集中在全球15亿用户的照片分析与存储上。根据《福布斯》的一项报道,谷歌在其照片存储服务 Google Photos 中被指

Meta 近日宣布,将开始使用来自欧洲用户的公开内容来训练其人工智能模型。这一决定是对去年因数据隐私问题而暂停训练工作后的恢复。Meta 表示,此次 AI 训练将主要依赖于在27个欧盟国家的成年用

Meta Platforms, Inc.宣布计划利用其在欧盟地区应用程序(包括Facebook和Instagram)的用户数据来训练人工智能模型。该公司明确指出,训练数据将包括用户的公开帖子、评论

在最近的高盛會議上,OpenAI 首席財務官莎拉・弗萊爾(Sarah Friar)透露,該公司正在開發一種名爲 “A-SWE” 的人工智能(AI)代理,旨在全面取代軟件工程師的工作。 弗萊爾表示
在最近的高盛会议上,OpenAI 首席财务官莎拉・弗莱尔(Sarah Friar)透露,该公司正在开发一种名为 “A-SWE” 的人工智能(AI)代理,旨在全面取代软件工程师的工作。 弗莱尔表示

近日,政策專家對的 AI 版權法規表示擔憂,認爲如果不提供全面的文本和數據挖掘豁免,可能會導致 AI 模型質量下降,進而影響創新。專家指出,禁止像 OpenAI、谷歌和 Meta 這樣的公司在英國
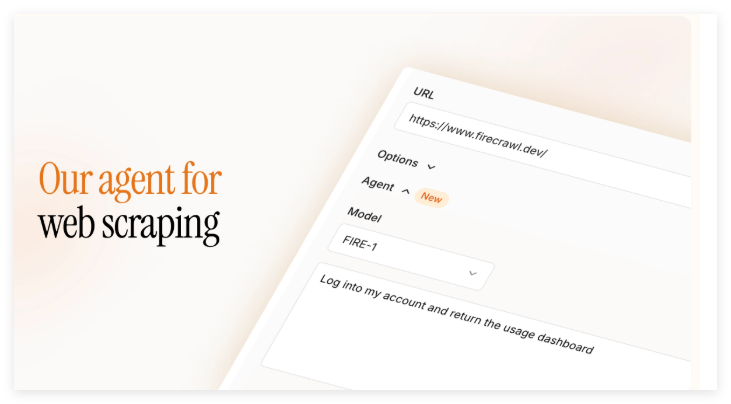
Firecrawl宣布推出其最新AI数据抓取工具FIRE-1,这标志着网页数据抓取技术迈向智能化新阶段。FIRE-1不仅延续了Firecrawl在高效数据提取领域的优势,还通过集成先进的AI交互能


