
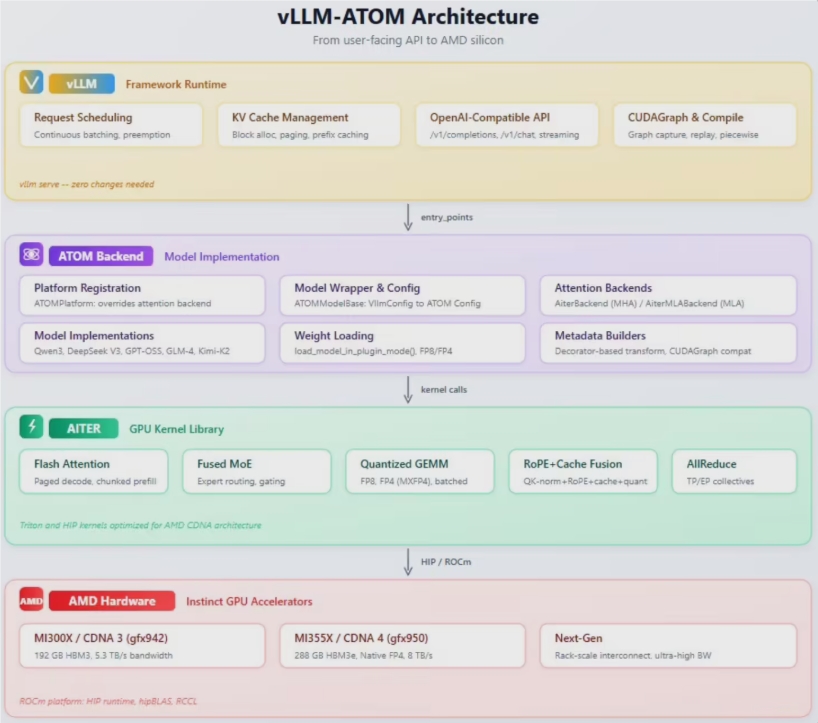
近日,AMD 正式发布了名为 vLLM-ATOM 的全新插件。这款工具的核心使命是在维持现有工作流不变的前提下,显著榨取硬件潜能,为 DeepSeek-R1、Kimi-K2以及 gpt-oss-1
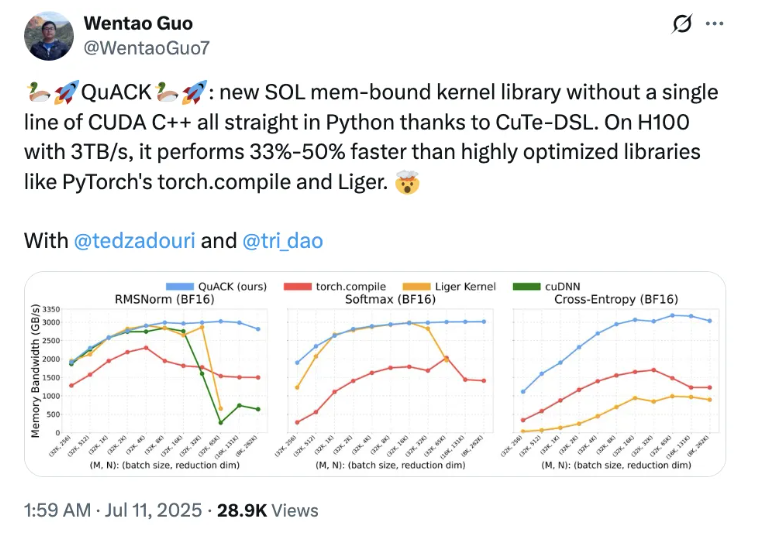
According to the latest report, Tri Dao, one of the co-authors of Flash Attention, together with t
最新の報道によると、Flash Attention の共同著者である Tri Dao は、プリンストン大学の2人の博士課程生と共同で、QuACK という新しいカーネルライブラリをリリースしました。


