

阿里云今日宣布,其研发的网络智能体 WebSailor 已正式开源。WebSailor 的构建方案及部分数据集目前已在 GitHub 上线,标志着阿里云在推动 AI 领域开放创新方面迈出了重要一步

在AI技术迅猛发展的今天,如何让AI智能体高效、安全地与数据库交互,成为开发者关注的焦点。2025年7月,谷歌重磅发布了MCP Toolbox for Databases,一款开源工具模块,旨在通
阿里雲今日宣佈,其研發的網絡智能體 WebSailor 已正式開源。WebSailor 的構建方案及部分數據集目前已在 GitHub 上線,標誌着阿里雲在推動 AI 領域開放創新方面邁出了重要一步
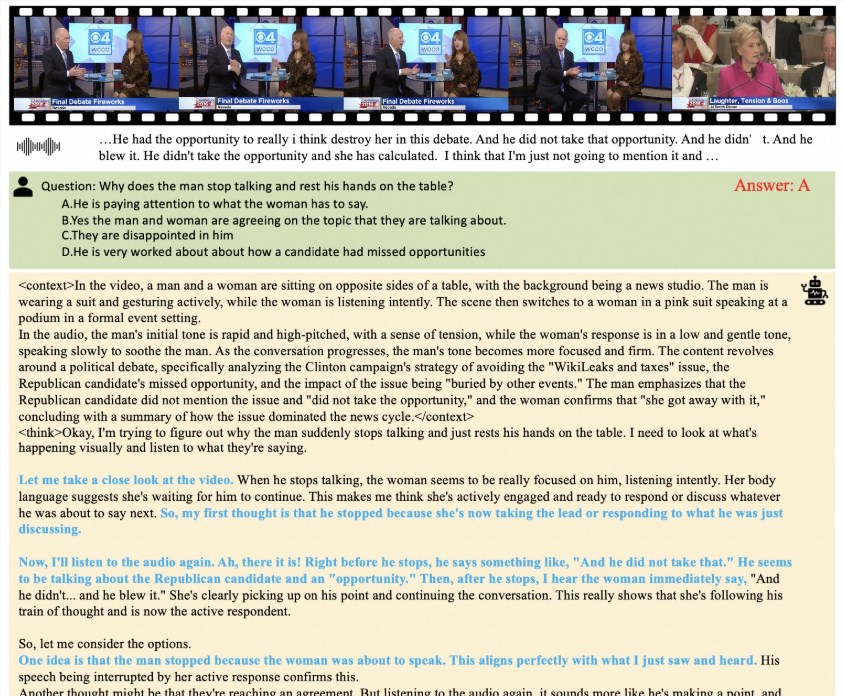
アリババグループは最近、最新のマルチモーダル大規模言語モデルHumanOmniV2を正式にリリースし、AI分野で再び注目を集めています。このモデルは、強力な全体的な文脈理解能力とマルチモーダル推論
Alibaba Group has recently officially launched its latest multimodal large language model HumanOmn
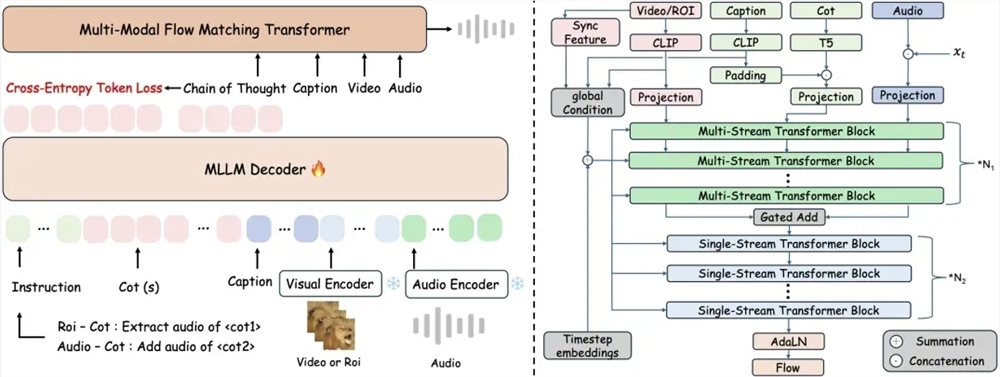
Recently, the Alibaba Speech AI team announced the open-source release of ThinkSound, the world's
近日,阿里语音AI团队宣布开源全球首个支持链式推理的音频生成模型ThinkSound,该模型通过引入思维链(Chain-of-Thought)技术,突破传统视频转音频技术对画面动态捕捉的局限,实现
近日,阿里語音AI團隊宣佈開源全球首個支持鏈式推理的音頻生成模型ThinkSound,該模型通過引入思維鏈(Chain-of-Thought)技術,突破傳統視頻轉音頻技術對畫面動態捕捉的侷限,實現

Alibaba Tongyi has officially open-sourced its network agent WebSailor, which possesses strong rea
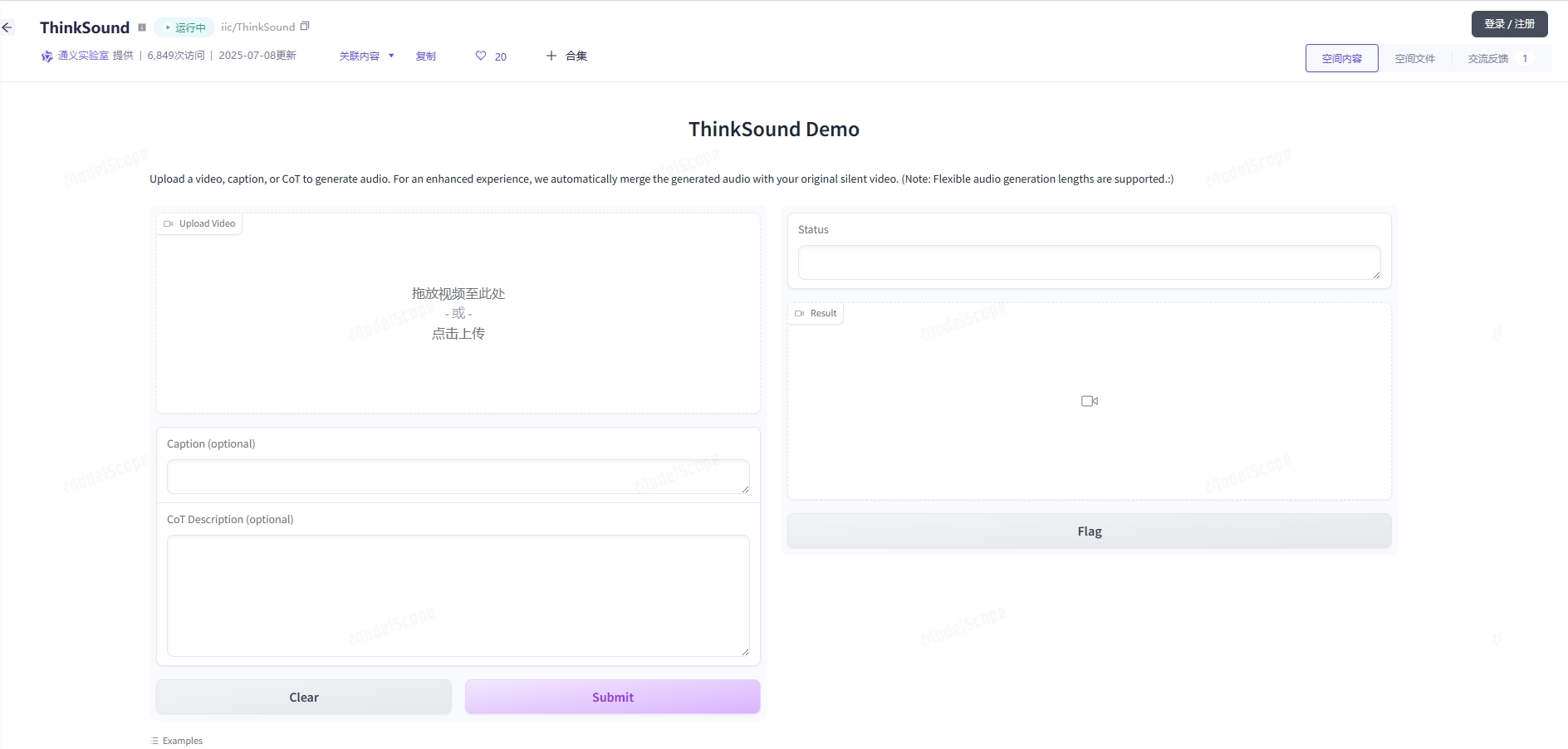
2025年7月,阿里巴巴通义实验室正式开源其首款音频生成模型ThinkSound,为视频内容创作带来革命性突破。这款多模态AI模型能够基于视频、文本或音频输入,生成高保真的音效与音景,完美适配画面


