
In July 2025, Alibaba's Tongyi Lab officially open-sourced its first audio generation model, Think
2025年7月,阿里巴巴通義實驗室正式開源其首款音頻生成模型ThinkSound,爲視頻內容創作帶來革命性突破。這款多模態AI模型能夠基於視頻、文本或音頻輸入,生成高保真的音效與音景,完美適配畫面
2025年7月、アリババ・トングイラボはその初の音声生成モデル「ThinkSound」を正式にオープンソース化しました。このモデルは動画コンテンツ制作に革命をもたらし、画期的な突破を実現しました。
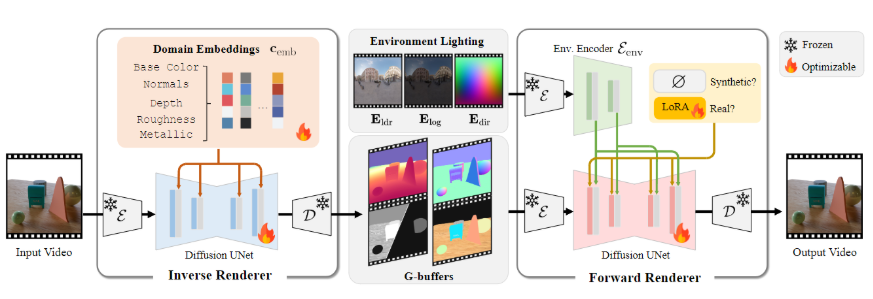
随着 AI 技术的迅猛发展,视频生成的质量正以惊人的速度提升,从最初模糊不清的片段发展到如今极具真实感的生成视频。然而,在这一进程中,缺乏对生成视频的控制和编辑能力,仍然是一个亟待解决的关键问题。
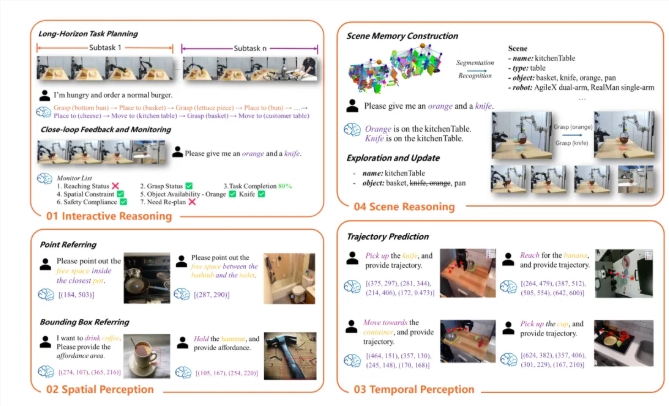
智源研究院は、身体知能システムの最新成果として、ロボットブレイン2.0 32Bバージョンおよび本体と小脳の協調フレームワークであるロボOS2.0単機版を正式に発表しました。ロボットブレイン2.0は
智源研究院正式發佈了具身智能系統的最新成果 ——RoboBrain2.032B 版本以及跨本體大小腦協同框架 RoboOS2.0單機版。RoboBrain2.0作爲一種 “通用具身大腦”,結合了感

近日,Anthropic旗下的AI助手Claude发布了一项重大更新:新增“应用和工具目录”,通过直观的界面支持用户快速链接和启用Model Context Protocol(MCP)服务。这一功

2025年7月15日 – 人工智能语音输入平台Willow Voice宣布成功完成420万美元天使轮融资,致力于推动语音优先交互技术的革新。本轮融资将用于优化其先进的语音输入技术,并加速实现打造通
2025年7月15日 – 人工智能語音輸入平臺Willow Voice宣佈成功完成420萬美元天使輪融資,致力於推動語音優先交互技術的革新。本輪融資將用於優化其先進的語音輸入技術,並加速實現打造通
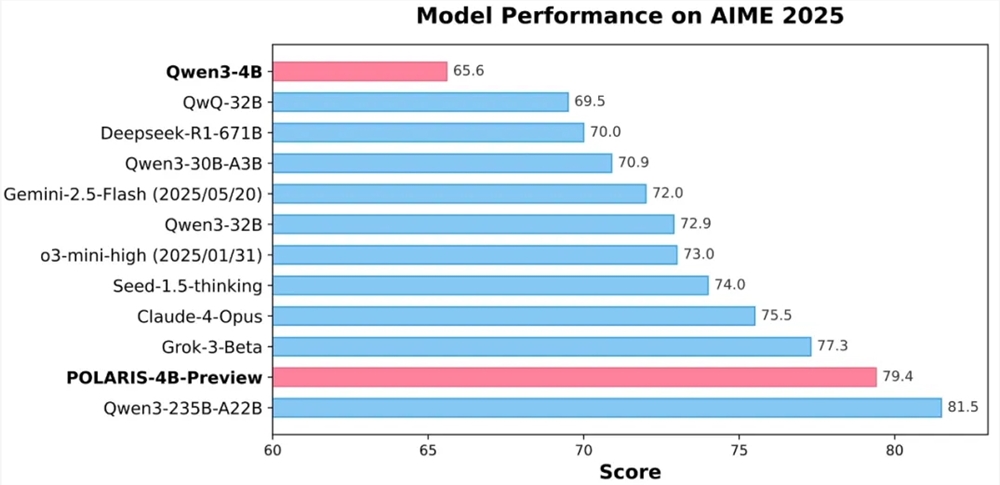
近日,字节跳动Seed团队携手香港大学与复旦大学,共同推出了创新的强化学习训练方法——POLARIS。该方法通过精心设计的Scaling RL策略,成功将小模型的数学推理能力提升至与超大模型相媲美


