
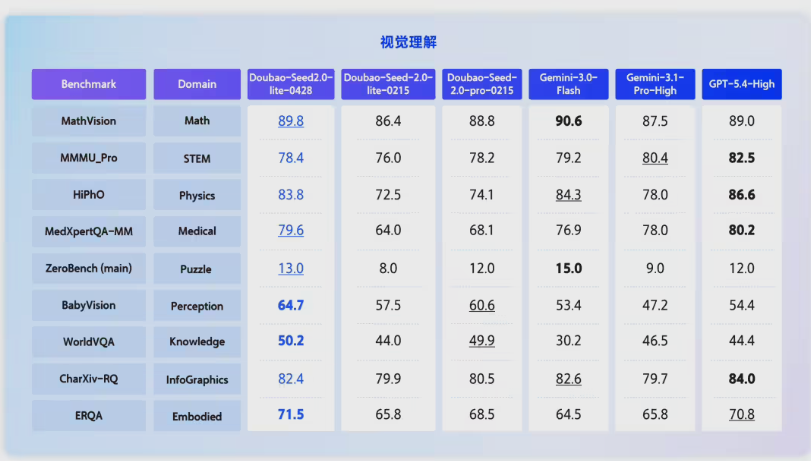
字节跳动旗下火山引擎于5月6日宣布,豆包大模型家族正式迎来首款全模态理解模型——Doubao-Seed-2.0-lite。作为该系列的重磅升级版本,新模型彻底打破了单一模态的限制,实现了视频、图像
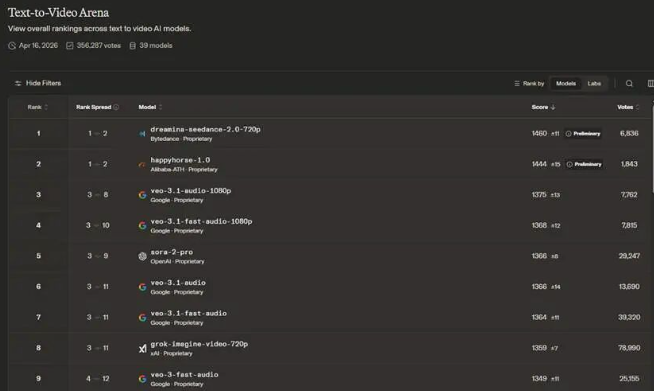
近日,阿里巴巴ATH创新事业部研发的新一代多模态视频生成模型HappyHorse正式开启灰度测试。作为全球AI视频领域的有力竞争者,该模型在Arena.ai的文生视频、图生视频及视频编辑三大核心榜
4月27日下午,千问APP首发灰测阿里视频模型HappyHorse,用户点击首页下方“HappyHorse”按钮即可体验。凭借该模型突出的叙事能力、音画同步和风格表现多样性,内测期间,创作者生成了

快手科技正式对外披露了其视频生成大模型产品可灵AI(Kling AI)的商业化进展。数据显示,截至2025年12月,可灵AI的单月营收已突破2000万美元。以此推算,其年化收入运行率(ARR)达到

以色列科技公司 Lightricks 近日宣布公开其最新视听合成系统 LTX-2。该系统具备极高的计算效能,能够根据简短的文本描述,直接生成长达20秒且音画完全同步的高清视频内容。 与传统的视觉

阿里通義實驗室近日發佈了一款名爲 “OmniTalker” 的新型數字人視頻生成大模型。這一創新模型的核心在於其能夠通過上傳一段參考視頻,實現對視頻中人物的表情、聲音和說話風格的精準模仿。相較於傳
阿里通义实验室近日发布了一款名为 “OmniTalker” 的新型数字人视频生成大模型。这一创新模型的核心在于其能够通过上传一段参考视频,实现对视频中人物的表情、声音和说话风格的精准模仿。相较于传
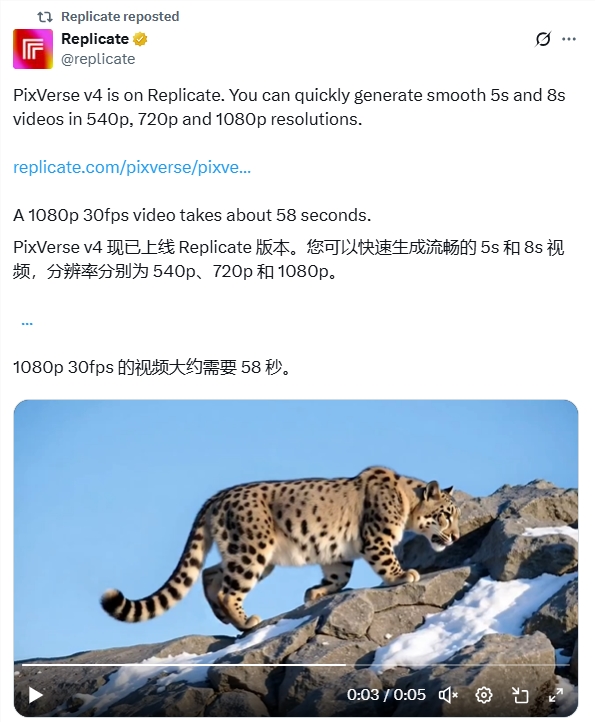
备受瞩目的 AI 视频生成工具 PixVerse v4正式在 Replicate 平台上线,为内容创作者们带来了前所未有的高清视频快速生成体验。新版本不仅支持生成5秒或8秒 的流畅视频片段,分辨率
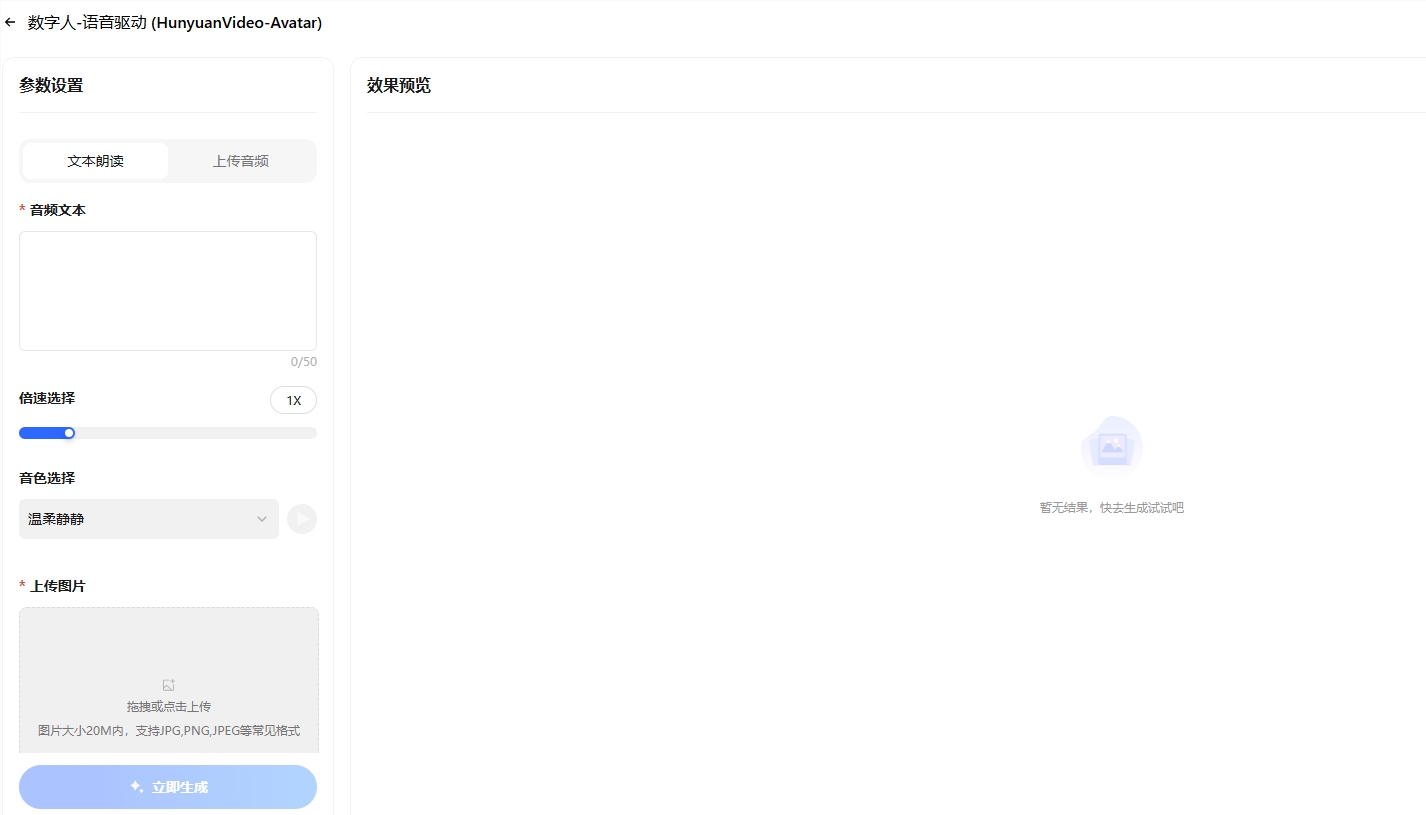
腾讯发布了一款创新技术 ——HunyuanVideo-Avatar 语音数字人模型,并将其开源。这一技术能够仅凭一张图片和一段音频,生成自然、真实的数字人说话或唱歌视频,标志着短视频创作进入了全新
騰訊發佈了一款創新技術 ——HunyuanVideo-Avatar 語音數字人模型,並將其開源。這一技術能夠僅憑一張圖片和一段音頻,生成自然、真實的數字人說話或唱歌視頻,標誌着短視頻創作進入了全新


