
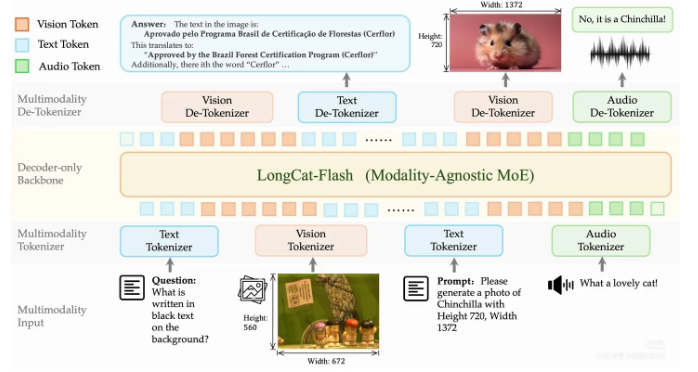
全球人工智能界正迎来一场关于“AI母语”的技术革新。针对当前大模型普遍存在的“以语言为中心、外挂视觉或语音模块”的拼凑式异构架构,大模型研发团队于近日正式发布并开源了全新原生多模态大模型 Long

近日,面壁智能联合清华大学及 OpenBMB 开源社区,正式发布并开源了中国首个基于华为昇腾平台训练的三值(1.58-bit)大模型 ——BitCPM-CANN。该模型在低比特大模型训练领域取得了
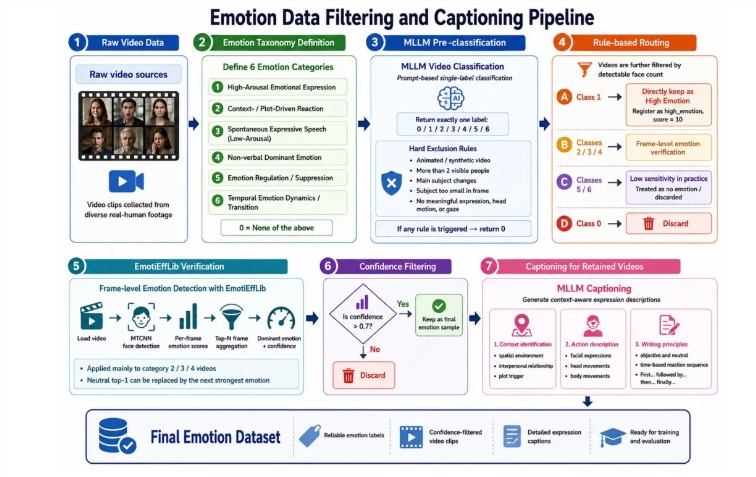
美团龙猫大模型团队今日宣布,正式开源商用级数字人视频生成模型——LongCat-Video-Avatar1.5。 该版本实现了从开源 SOTA(最高水平)向商业级实际应用的全面跨越,在唇形同步、物
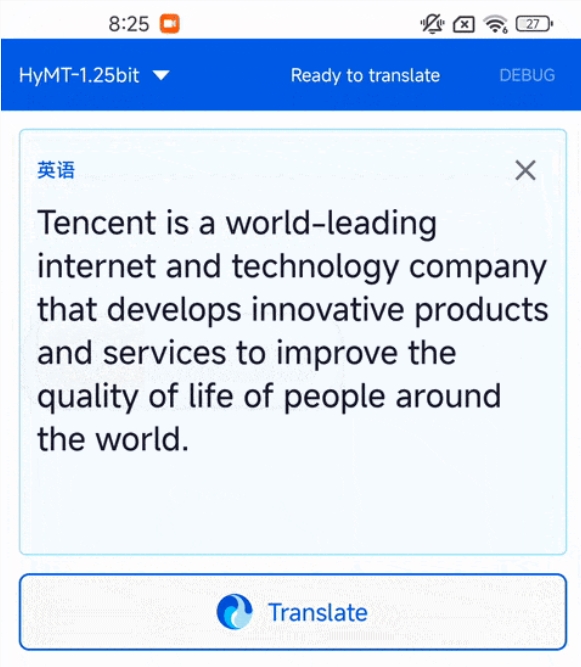
4月29日,腾讯混元团队宣布正式开源其极限量化压缩版的翻译模型——Hy-MT1.5-1.8B-1.25bit。这款模型最大的亮点在于,它将支持33种语言的翻译能力精准压缩到了440MB左右,这意味
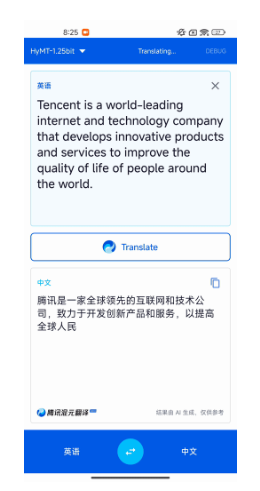
随着五一黄金周临近,腾讯混元团队近日发布了其专业翻译大模型的极致量化版本,为计划出国旅游的用户提供了硬核的语言解决方案。这款名为Hy-MT1.5-1.8B-1.25bit的模型仅有440MB,支持

小米在机器人技术领域再次抛出“重磅炸弹”。继今年2月发布并开源其VLA大模型Xiaomi-Robotics-0后,小米于今日正式公布了该模型的真机后训练(Post-training)全流程。这一举

音频生成技术正迎来从级联架构向端到端生成的范式转移。针对传统 TTS 系统因“梅尔频谱”中间表征带来的信息损耗与误差累积,美团 LongCat 团队于今日正式发布并开源了 LongCa
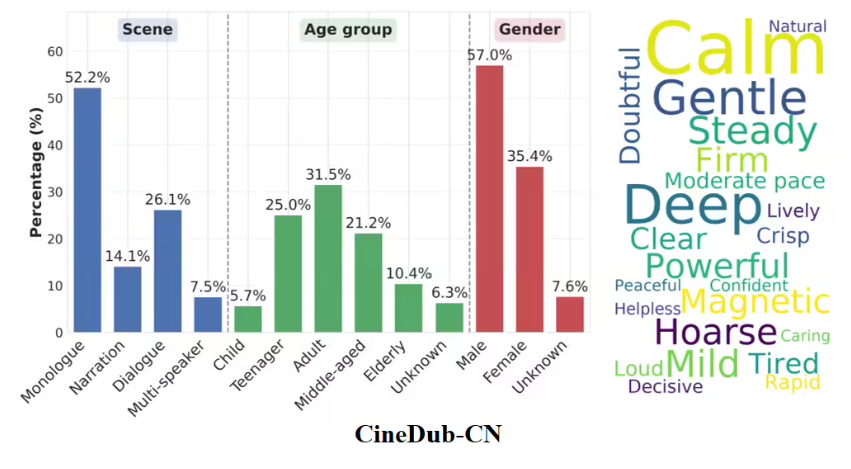
阿里通义实验室于3月16日正式发布并开源了影视级多场景配音多模态大模型 Fun-CineForge。该模型旨在解决 AI 配音中长期存在的口型不同步、情感表达缺失以及多角色音色不一致等核心痛点,并
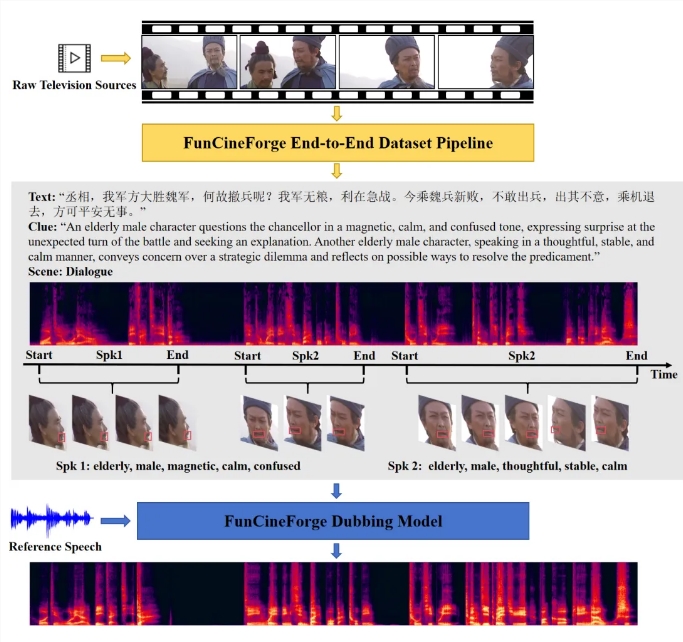
传统的 AI 配音在面对影视、动画等高标准场景时,常因难以匹配复杂的情绪爆发和精准口型而遭遇瓶颈。针对这一痛点,通义实验室正式发布并开源了首个影视级多场景配音多模态大模型——
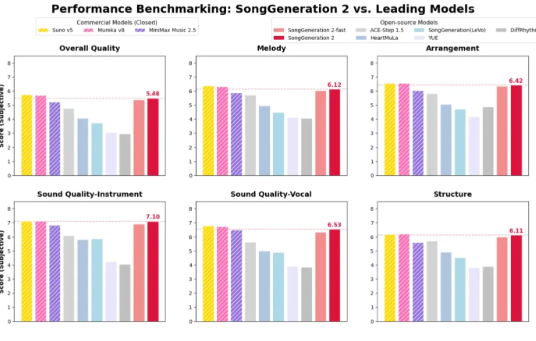
AI 音乐赛道在2026年初迎来了又一次震撼余震。3月9日,由 腾讯与清华大学人机语音交互实验室 联合研发的音乐基础模型 SongGenerat


