

音频生成技术正迎来从级联架构向端到端生成的范式转移。针对传统 TTS 系统因“梅尔频谱”中间表征带来的信息损耗与误差累积,美团 LongCat 团队于今日正式发布并开源了 LongCa
近日,英偉達在 Hugging Face 平臺上推出了其最新的自動語音識別(ASR)模型 ——Parakeet-TDT-0.6B-V2。這一新模型不僅在性能上有顯著提升,還將開源理念與商業應用相結

人工知能領域の急速な発展の中で、国産の大規模モデルの進化速度には驚かされます。今年の初めには、DeepSeek-R1が低コストでOpenAIを上回る性能を示し、海外の大規模モデルによる市場の独占的

最近、通義大模型はCoGenAVを発表しました。これは音声と映像の同期というアイデアに基づいて音声認識技術を革新し、雑音干渉による問題を効果的に解決しています。 従来の音声認識技術はノイズ環境
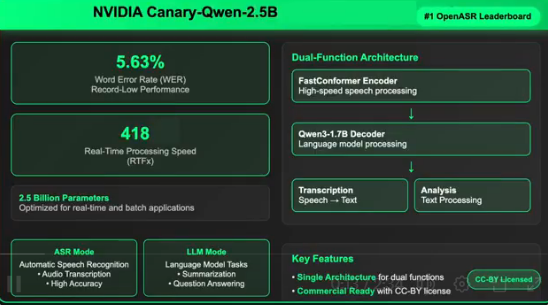
NVIDIA刚刚发布了Canary-Qwen-2.5B,这是一款突破性的自动语音识别(ASR)和语言模型(LLM)混合模型,以创纪录的5.63%词错率(WER)荣登Hugging Face Ope


