
Qwen3-30B-A3Bモデルは大きなアップデートを受け、新バージョンのQwen3-30B-A3B-Thinking-2507がリリースされました。この新しいバージョンは、推論能力、汎用性、およ
Qwen3-30B-A3B模型迎来了重大更新,推出了新版本Qwen3-30B-A3B-Thinking-2507。这一新版本在推理能力、通用能力及上下文长度上实现了显著提升,标志着该模型不仅更加轻
Qwen3-30B-A3B模型迎來了重大更新,推出了新版本Qwen3-30B-A3B-Thinking-2507。這一新版本在推理能力、通用能力及上下文長度上實現了顯著提升,標誌着該模型不僅更加輕
阿里雲通義實驗室近日宣佈正式開源其自主搜索AI智能體項目 WebAgent,其中旗艦組件 WebShaper 和 WebSailor 在網絡智能體領域引發廣泛關注。作爲一款突破性的AI工具,Web
阿里云通义实验室近日宣布正式开源其自主搜索AI智能体项目 WebAgent,其中旗舰组件 WebShaper 和 WebSailor 在网络智能体领域引发广泛关注。作为一款突破性的AI工具,Web

近日,魔搭ModelScope社区宣布发布一项名为UGMathBench的动态基准测试数据集,旨在全面评估语言模型在本科数学广泛科目中的数学推理能力。这一数据集的问世,填补了当前在本科数学领域评估

由清華大學語音與語言實驗室(Tencent AI Lab)聯合上海創智學院、復旦大學和模思智能打造的MOSS-TTSD(Text to Spoken Dialogue)近日正式開源,標誌着AI語音

由清华大学语音与语言实验室(Tencent AI Lab)联合上海创智学院、复旦大学和模思智能打造的MOSS-TTSD(Text to Spoken Dialogue)近日正式开源,标志着AI语音

清华大学音声・言語実験室(テンセントAIラボ)が上海創智学院、復旦大学、モーススマートと共同で開発したMOSS-TTSD(Text to Spoken Dialogue)が近日オープンソース化され
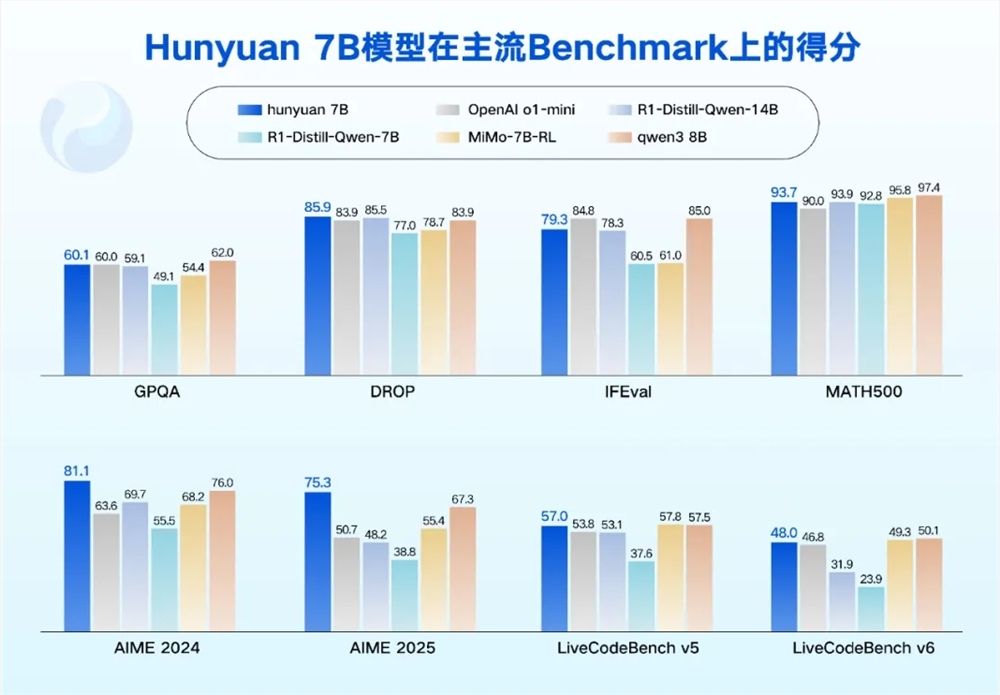
腾讯混元团队宣布推出四款开源的小尺寸模型,参数分别为0.5B、1.8B、4B和7B。这些模型专为消费级显卡设计,适用于笔记本电脑、手机、智能座舱、智能家居等低功耗场景,并支持垂直领域的低成本微调。


