
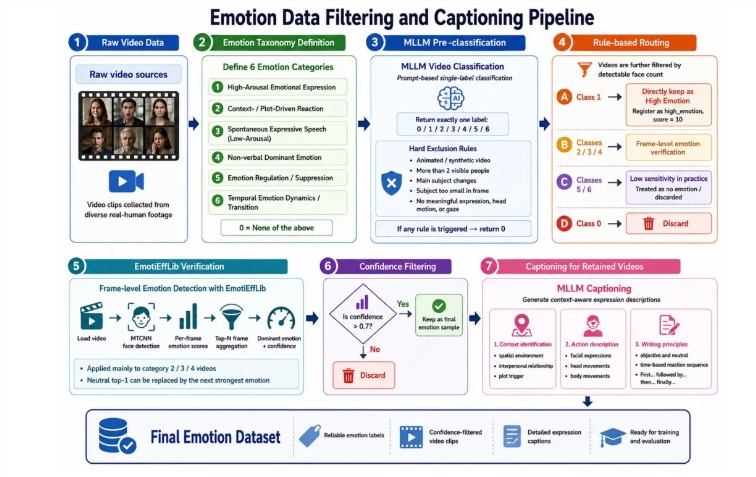
美团龙猫大模型团队今日宣布,正式开源商用级数字人视频生成模型——LongCat-Video-Avatar1.5。 该版本实现了从开源 SOTA(最高水平)向商业级实际应用的全面跨越,在唇形同步、物

近日,研究人员正式发布LPM1.0模型,该研究项目旨在通过单张参考图像实时生成涵盖说话、聆听及唱歌行为的人物视频。LPM1.0的核心突破在于其多模态处理能力,能同步整合文本、音频与图像输入,生成具

快手近日将其视频生成器Kling升级至2.6版本,推出语音控制和动作控制两大核心功能,为AI视频生成领域带来突破性进展。此次更新不仅实现了原生音频生成,还大幅提升了复杂动作的处理精度。 语音
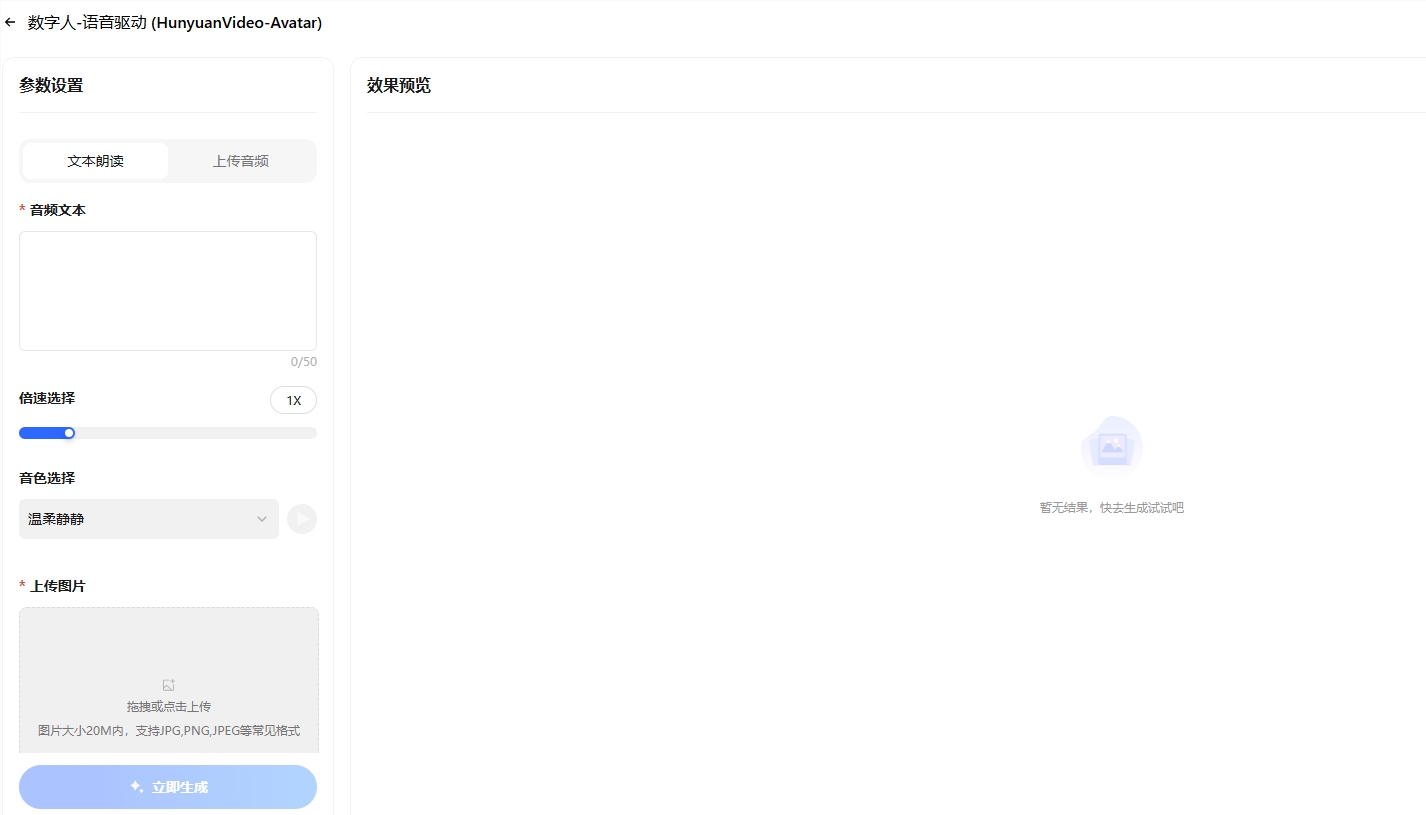
腾讯发布了一款创新技术 ——HunyuanVideo-Avatar 语音数字人模型,并将其开源。这一技术能够仅凭一张图片和一段音频,生成自然、真实的数字人说话或唱歌视频,标志着短视频创作进入了全新


