
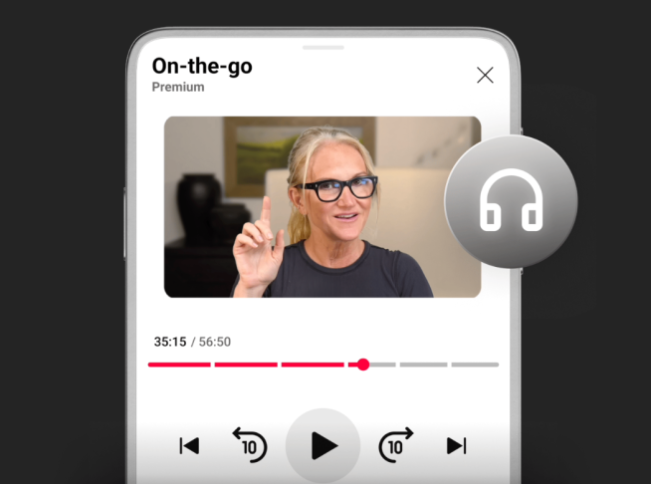
为了与疯狂加码视频播客的流媒体巨头展开竞争,并吸引Spotify和苹果播客的音频核心受众,YouTube于周四宣布针对Premium订阅用户推出一系列播客全新功能。本次更新的核心在于通过个性化探索
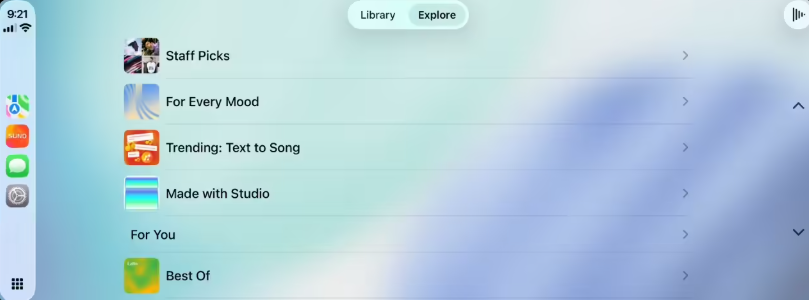
近日,科技媒体 9to5Mac 报道苹果 CarPlay 第三方应用系统再扩展,迎来了两款全音频应用之一便是 uno。这款基于智能的音乐生成应用用户无需具音乐创作专业知识需输入简单文字提示,就生成

谷歌近日在Gemini3.1系列中正式推出全新文字转语音模型Gemini-TTS,官方给出的定位直接而自信:"至今最富表现力的文本转语音解决方案"。 这款模型最核心的突破,在于把语音的"控制权"

近日,研究人员正式发布LPM1.0模型,该研究项目旨在通过单张参考图像实时生成涵盖说话、聆听及唱歌行为的人物视频。LPM1.0的核心突破在于其多模态处理能力,能同步整合文本、音频与图像输入,生成具
近日,AI 技術公司 Perplexity 在官方渠道上宣佈推出一款全新的 AI 語音助手,專爲 iOS 平臺用戶設計。這款助手旨在爲用戶提供與蘋果原生的 Siri 相似的使用體驗,力求在生活和工

最近の財務電話会議で、Spotifyの最高製品・技術責任者であるグスタフ・ソデルストロム氏は、人工知能技術の進展に伴い、今後のSpotifyのユーザー体験がより「インタラクティブ」になるだろうと明
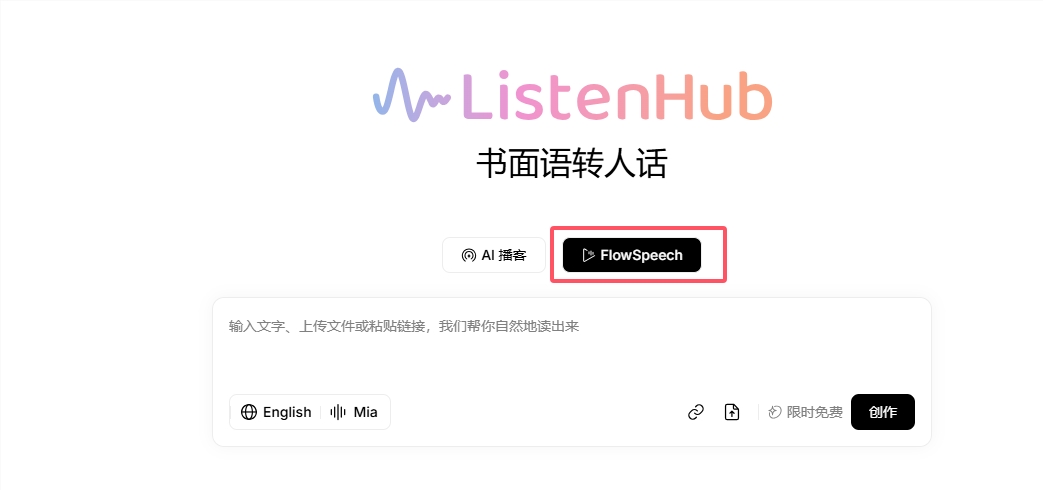
Artificial intelligence speech synthesis technology has made a new breakthrough. A text-to-speech

人工智能音頻領域的領軍企業ElevenLabs再次掀起行業波瀾,於今日正式推出一款基於 AI 的可定製音效控制面板工具——SB-1Infinite Soundboard。 用戶可以通過點
人工智能音频领域的领军企业ElevenLabs再次掀起行业波澜,于今日正式推出一款基于 AI 的可定制音效控制面板工具——SB-1Infinite Soundboard。 用户可以通过点
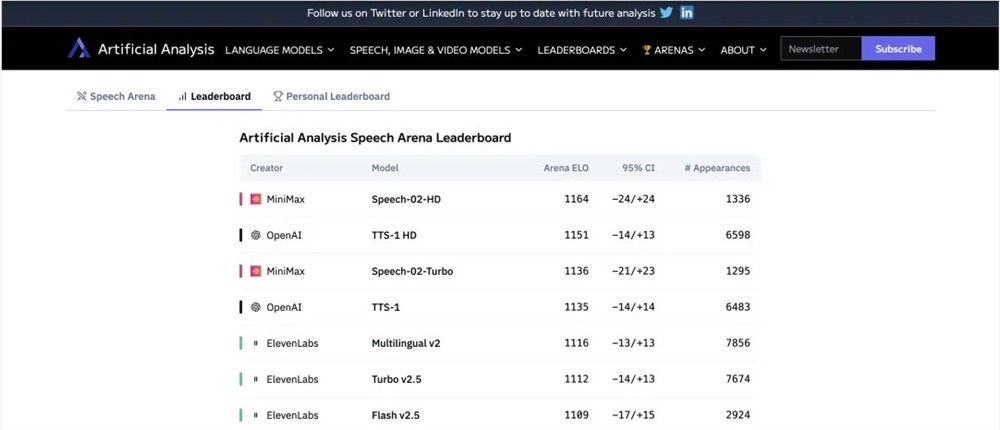
MiniMax Audio推出的Speech-02系列语音模型席卷全球,强势登顶Artificial Analysis Speech Arena和Hugging Face TTS Arena两大权


