最近の財務電話会議で、Spotifyの最高製品・技術責任者であるグスタフ・ソデルストロム氏は、人工知能技術の進展に伴い、今後のSpotifyのユーザー体験がより「インタラクティブ」になるだろうと明
Artificial intelligence speech synthesis technology has made a new breakthrough. A text-to-speech
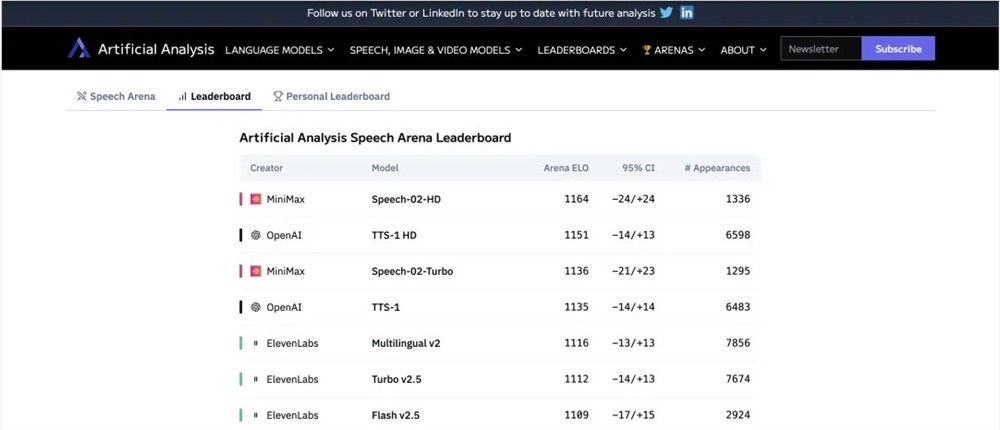
MiniMax Audio推出的Speech-02系列语音模型席卷全球,强势登顶Artificial Analysis Speech Arena和Hugging Face TTS Arena两大权

有名なAIスタートアップの李沐(リ・ム)と彼のチームBoson.aiは、最近新しいオープンソースのテキストから音声への変換(TTS)大規模モデル「Higgs Audio v2」をリリースしました。
Google发布Gemini2.5Flash与Pro文本转语音预览模型,全面替代今年5月旧版系统。新模型主打「情绪级」表达、上下文自适应节奏及24语种多角色对话,开发者现可在Google AI S
阿里通义千问发布新一代语音合成大模型Qwen3-TTS,即日起通过Qwen API向全球开发者免费开放。模型提供49种多角色音色,支持10种主流语言及10种中国方言,官方称其在MiniMax TT