

阿里通義實驗室近日發佈了一款名爲 “OmniTalker” 的新型數字人視頻生成大模型。這一創新模型的核心在於其能夠通過上傳一段參考視頻,實現對視頻中人物的表情、聲音和說話風格的精準模仿。相較於傳

人工智能领域迎来一项重大突破。AIbase从社交媒体获悉,字节跳动于近日宣布开源其全新多模态生成模型Liquid,该模型以创新的统一编码方式和单一大语言模型(LLM)架构,实现了视觉理解与生成任务
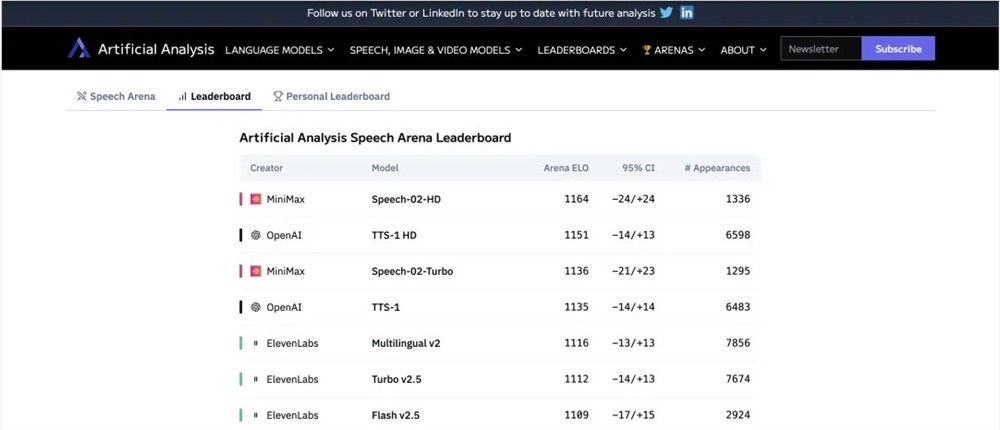
MiniMax Audio推出的Speech-02系列语音模型席卷全球,强势登顶Artificial Analysis Speech Arena和Hugging Face TTS Arena两大权
MiniMax Audio推出的Speech-02系列語音模型席捲全球,強勢登頂Artificial Analysis Speech Arena和Hugging Face TTS Arena兩大權
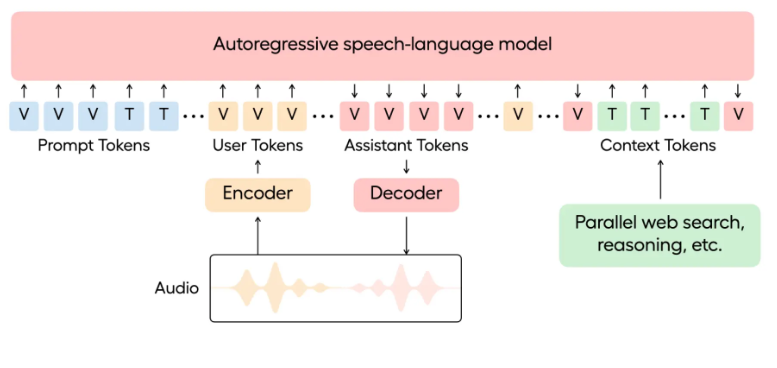
Hume公司於2025年5月29日正式發佈全新語音語言模型EVI3,這一創新標誌着通用語音智能領域的重大飛躍。相較於傳統文本到語音(TTS)模型,EVI3不僅能夠理解和生成任意人類語音,還能精準捕


