

近日,通义大模型发布CoGenAV,以音画同步理念创新语音识别技术,有效解决语音识别中噪声干扰的难题。 传统语音识别在噪声环境下表现欠佳,CoGenAV则另辟蹊径,通过学习audio-visua
近日,通義大模型發佈CoGenAV,以音畫同步理念創新語音識別技術,有效解決語音識別中噪聲干擾的難題。 傳統語音識別在噪聲環境下表現欠佳,CoGenAV則另闢蹊徑,通過學習audio-visua
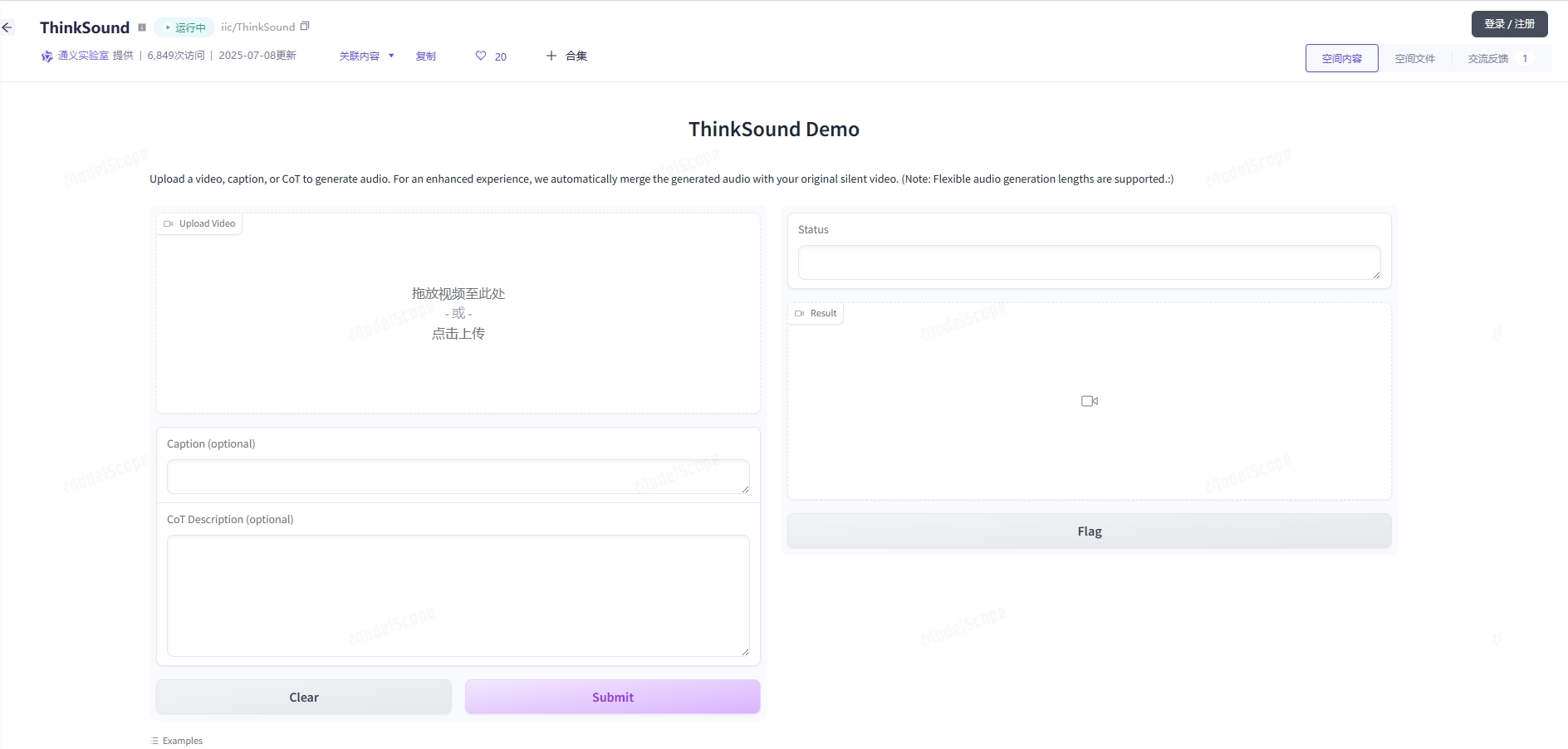
2025年7月,阿里巴巴通义实验室正式开源其首款音频生成模型ThinkSound,为视频内容创作带来革命性突破。这款多模态AI模型能够基于视频、文本或音频输入,生成高保真的音效与音景,完美适配画面
2025年7月,阿里巴巴通義實驗室正式開源其首款音頻生成模型ThinkSound,爲視頻內容創作帶來革命性突破。這款多模態AI模型能夠基於視頻、文本或音頻輸入,生成高保真的音效與音景,完美適配畫面
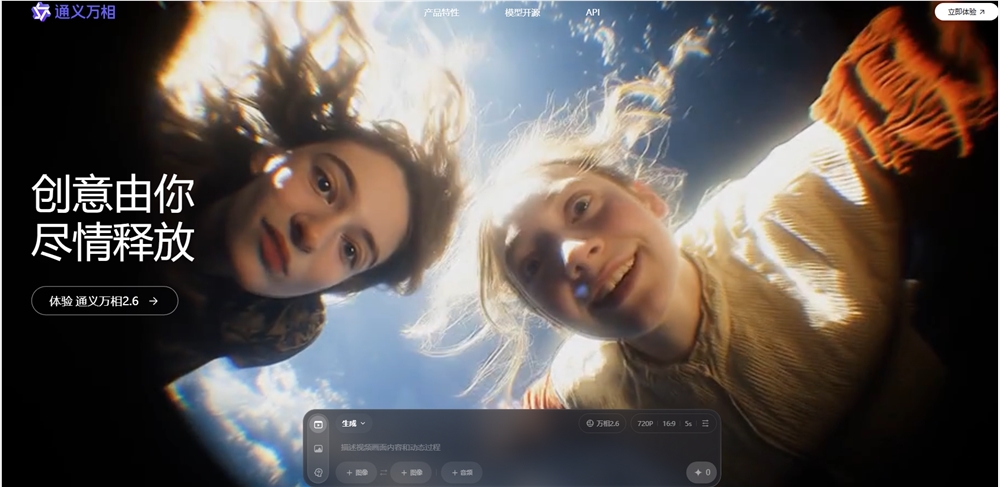
12月16日,阿里巴巴宣布推出新一代 万相2.6系列模型,该模型针对专业影视制作和图像创作场景进行了全面升级,并被称为**“全球功能最全的视频生成模型”。万相2.6已同步上线阿里云百炼和万相官网*


