
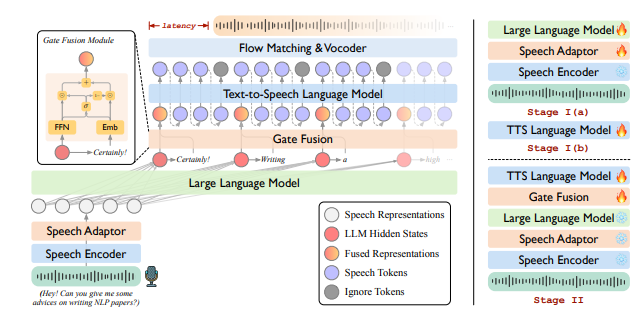
最近 AI 圈可是熱鬧非凡,今天咱們就來聊聊其中的 “狠角色”——LLaMA-Omni2。這是一系列超厲害的語音語言模型(SpeechLMs),參數規模從0.5B 到14B 不等,專門爲實現高質量

近日,通义大模型发布CoGenAV,以音画同步理念创新语音识别技术,有效解决语音识别中噪声干扰的难题。 传统语音识别在噪声环境下表现欠佳,CoGenAV则另辟蹊径,通过学习audio-visua
近日,通義大模型發佈CoGenAV,以音畫同步理念創新語音識別技術,有效解決語音識別中噪聲干擾的難題。 傳統語音識別在噪聲環境下表現欠佳,CoGenAV則另闢蹊徑,通過學習audio-visua
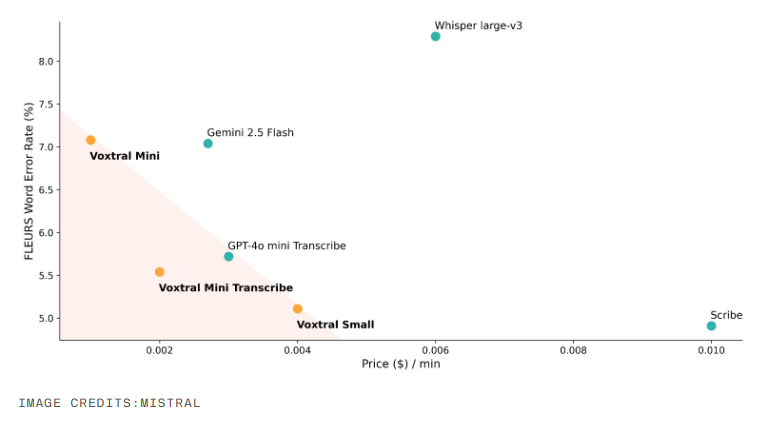
隨着人工智能技術的飛速發展,語音正迅速成爲我們與機器溝通的主要方式。法國初創企業 Mistral 近日正式發佈了其首個開源音頻模型 ——Voxtral,旨在打破大型企業封閉系統的壟斷,爲開發者提供
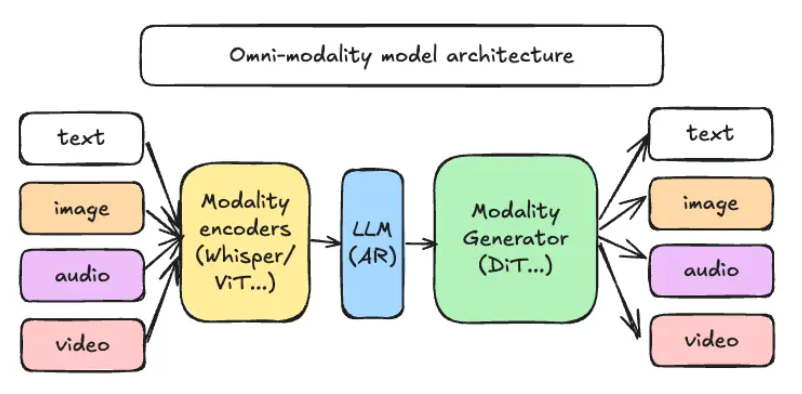
vLLM团队发布首个“全模态”推理框架vLLM-Omni,将文本、图像、音频、视频的统一生成从概念验证变成可落地代码。新框架已上线GitHub与ReadTheDocs,开发者可立即pip安装并调用


