登录之后可以开启更多功能哦
近日,通義大模型發佈CoGenAV,以音畫同步理念創新語音識別技術,有效解決語音識別中噪聲干擾的難題。 傳統語音識別在噪聲環境下表現欠佳,CoGenAV則另闢蹊徑,通過學習audio-visua
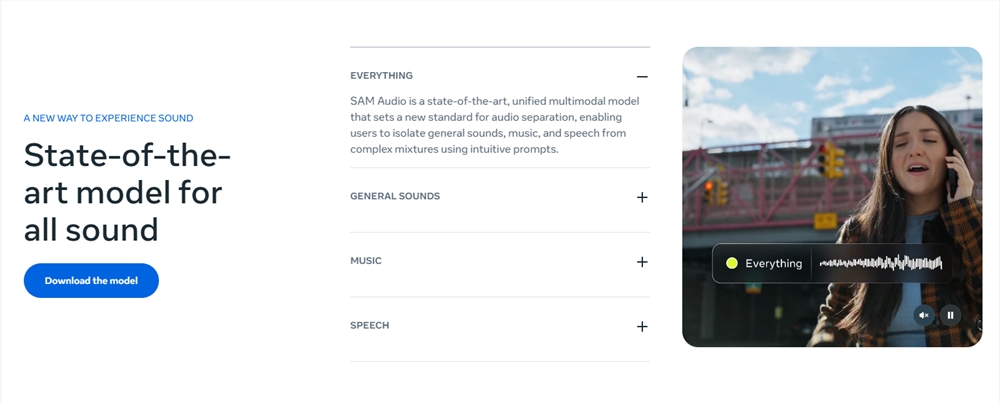
Meta正式推出音频处理领域的重磅突破——SAM Audio,全球首个统一的多模态音频分离模型。它能让用户像“用眼睛听声音”一样,从一段混杂的视频或音频中,一键提取出任意目标声音:点击视频中的吉他