
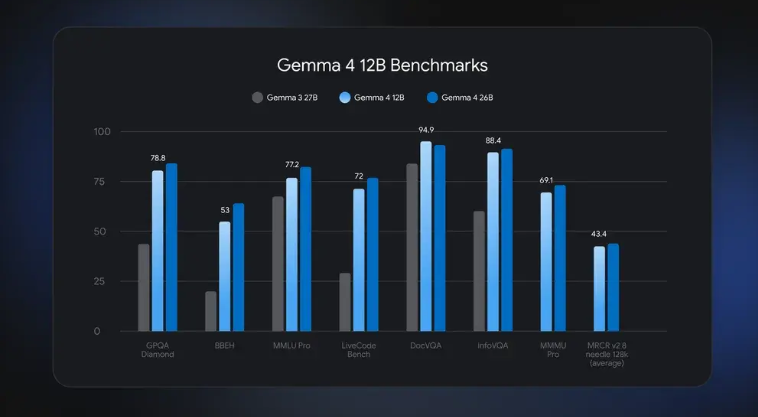
全球开源大模型生态迎来架构层面的颠覆性突破。谷歌于6月3日正式发布了全新统一多模态模型 Gemma412B 。该模型最大的创新在于彻底取消了传统多模态模型必不可少
北京时间5月13日,Apple Silicon 本地 AI 生态迎来重要进展。oMLX 框架0.3.9.dev2版本发布,深度集成多项前沿优化技术,显著提升了本地大模型的图文处理速度与易用性,进一
谷歌近期推出了 Gemma3系列的全新版本,這一消息讓衆多 AI 愛好者爲之振奮。僅在上線一個月後,谷歌便發佈了經過量化感知訓練(QAT)優化的 Gemma3,旨在顯著降低內存需求的同時,保持模型
谷歌近期推出了 Gemma3系列的全新版本,这一消息让众多 AI 爱好者为之振奋。仅在上线一个月后,谷歌便发布了经过量化感知训练(QAT)优化的 Gemma3,旨在显著降低内存需求的同时,保持模型
Recently, MLX-LM has been directly integrated into the Hugging Face platform. This milestone updat

アップルは、Apple Siliconチップ向けに設計された機械学習フレームワーク「MLX」にNVIDIAのCUDAサポートを追加しています。この画期的な進展により、AI開発者にとってこれまでにな


