

近日,有消息称,这家市值万亿美元的科技巨头在一项集体诉讼中被指控曾直接联系安娜档案馆(Anna's Archive),试图获取高达 500TB 的盗版电子书数据,以用于其大模型的训练。这一行为引发

全球芯片巨头 英伟达 (NVIDIA)近期因 AI 模型训练数据来源问题深陷法律纠纷。一份最新提交给美国加州法院的修正起诉书披露了惊人细节:英伟达被指控为了在竞争
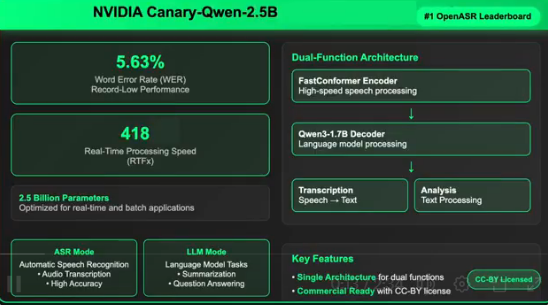
NVIDIA剛剛發佈了Canary-Qwen-2.5B,這是一款突破性的自動語音識別(ASR)和語言模型(LLM)混合模型,以創紀錄的5.63%詞錯率(WER)榮登Hugging Face Ope
NVIDIA刚刚发布了Canary-Qwen-2.5B,这是一款突破性的自动语音识别(ASR)和语言模型(LLM)混合模型,以创纪录的5.63%词错率(WER)荣登Hugging Face Ope


