
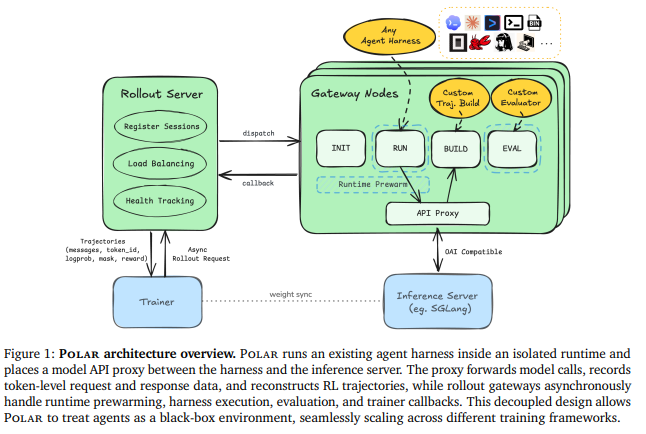
5月28日,英伟达(NVIDIA)研究团队正式开源了名为 Polar 的强化学习训练框架。该框架的核心创新在于,它能够让 Codex、Claude Code、Qwen Code 等现有主流代码智能
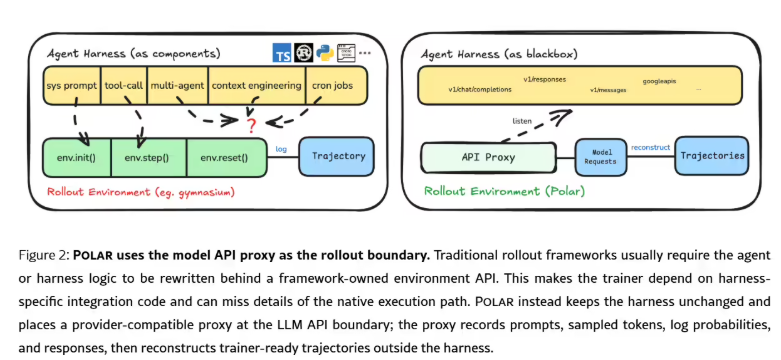
英伟达研究团队近日发布了一个全新的开源 AI 框架 ——Polar。该框架旨在帮助现有的智能体框架(如 Codex、Claude Code、Qwen Code)接入一种名为广义相对策略优化(GRP
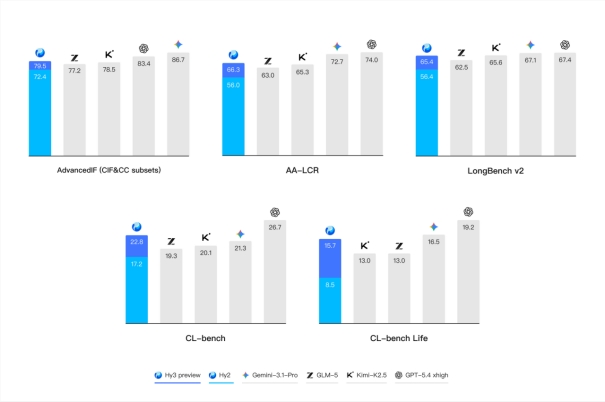
4月23日,腾讯混元 Hy3preview 语言模型发布并开源。这是一个快慢思考融合的混合专家模型,总参数295B,激活参数21B,最大支持256K 上下文长度。这是混元重建后训练的第一个模型,也

4月22日,阿里云通义千问团队宣布其开源家族迎来重磅更新,正式发布270亿参数的稠密多模态模型——Qwen3.6-27B。作为开发者群体呼声最高的模型规格,该版本的出现不仅完善了Qwen系列的产品

据报道,继 GLM-5.1和 MiniMax2.7之后, 月之暗面 正式推出了专为 AI 编程优化的万亿参数大模型 —— Kimi K2.6-code-p

研究机构 METR 最新发布的一项研究显示,被广泛用于评估 AI 编程能力的基准测试 SWE-bench Verified 可能显著高估了 AI 代理在真实软件开发环境中的表现。研究发现,在基准测
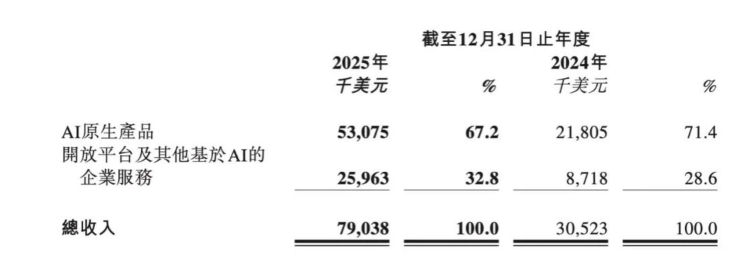
2026年3月2日, MiniMax(上海稀宇科技) 发布了其上市后的首份年度成绩单。这份报告不仅是数字的堆叠,更是对“AI 时代平台型公司”这一新叙事框架的实战推演。
| 微软今日宣布正式向网页、Windows 及移动端用户推送 OpenAI 迄今为止最强大的模型系列——GPT-5.2。作为一次极具诚意的免费升级,GPT-5.2将以“智能增强版”模式与现有的 G
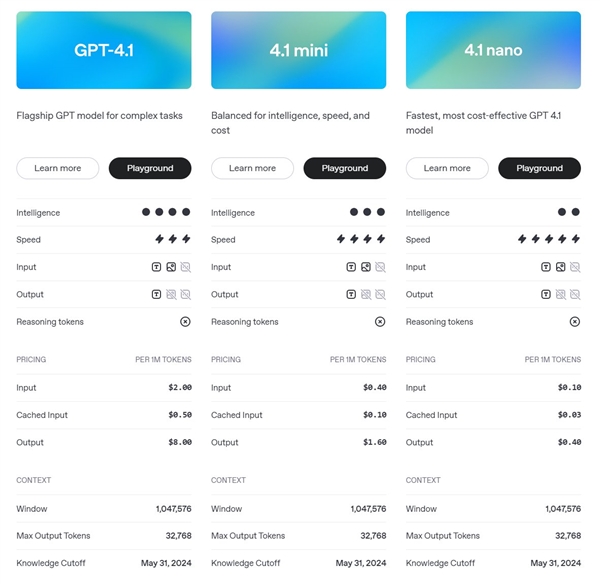
4月15日,OpenAI 在其官方博客宣布正式发布 GPT-4.1系列模型,涵盖 GPT-4.1、GPT-4.1mini 和 GPT-4.1nano 三款子模型。该系列在编程能力、指令理解及长文本
4月15日、OpenAIは公式ブログでGPT-4.1シリーズモデルの正式リリースを発表しました。GPT-4.1、GPT-4.1mini、GPT-4.1nanoの3つのサブモデルが含まれています。こ


