登录之后可以开启更多功能哦
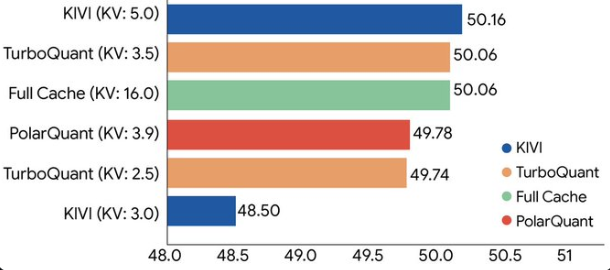
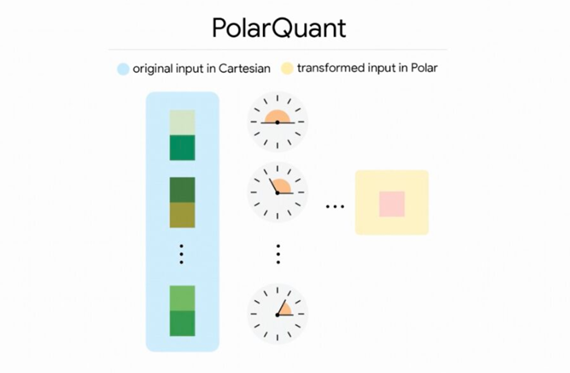
3月26日消息,谷歌研究团队(Google Research)近日正式推出全新向量量化压缩算法TurboQuant,通过创新的 PolarQuant 与 QJL 技术,将大语言模型(LLM)推理过
在大语言模型(LLM)的推理过程中,内存瓶颈一直是制约性能的“头号杀手”。每当 AI 处理长文本或生成复杂回答时,一种被称为 KV 缓存(Key-Value Cache)的“工作内存”就会迅速膨胀