
在大语言模型(LLM)的推理过程中,内存瓶颈一直是制约性能的“头号杀手”。每当 AI 处理长文本或生成复杂回答时,一种被称为 KV 缓存(Key-Value Cache)的“工作内存”就会迅速膨胀

大模型领域的“核弹级”更新似乎正呼之欲出。2026年3月2日,全球开发者社区因一次意外的代码提交而陷入疯狂。 OpenAI 的一名工程师在公开的 Codex 代码仓库中,不
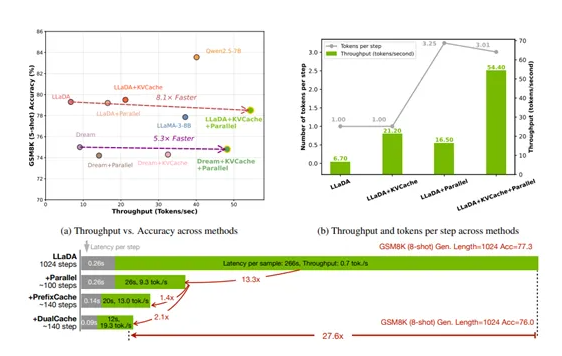
近日,英偉達、香港大學與麻省理工學院的研究團隊聯合發佈了一種名爲 Fast-dLLM 的創新技術,旨在提升擴散語言模型的推理效率。與傳統的自迴歸模型不同,擴散語言模型採用逐步去除文本噪聲的方式生成
近日,英伟达、香港大学与麻省理工学院的研究团队联合发布了一种名为 Fast-dLLM 的创新技术,旨在提升扩散语言模型的推理效率。与传统的自回归模型不同,扩散语言模型采用逐步去除文本噪声的方式生成
最近、NVIDIA、香港大学およびマサチューセッツ工科大学の研究チームは、拡散言語モデルの推論効率を向上させるための新技術「Fast-dLLM」を発表しました。従来の自己回帰モデルとは異なり、拡散


