
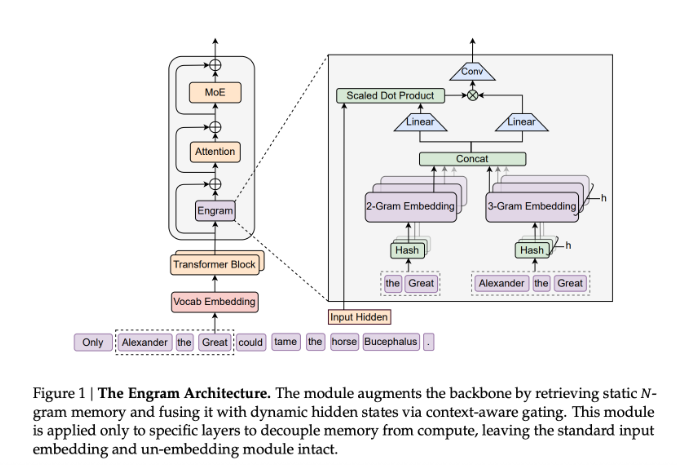
传统的 Transformer 模型在处理重复性知识时往往显得有些“浪费”,每次遇到相同的模式都需要重新计算,这不仅消耗深度也浪费了计算资源。为了打破这一瓶颈,DeepSeek 的研究团队近日推出
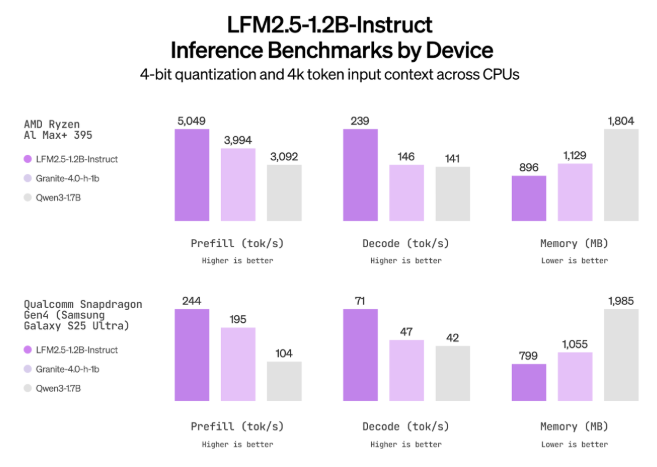
Liquid AI 最近推出了 LFM2.5,这是一个新一代的小型基础模型家族,基于 LFM2架构,专注于边缘设备和本地部署。该模型家族包括 LFM2.5-1.2B-Base 和 LFM2.5-1

近日,知名 AI 实验室 DeepSeek 发表了一项极具影响力的研究论文,揭示了通过优化神经网络架构而非仅仅增加模型规模,也能大幅提升大语言模型的推理表现。这一
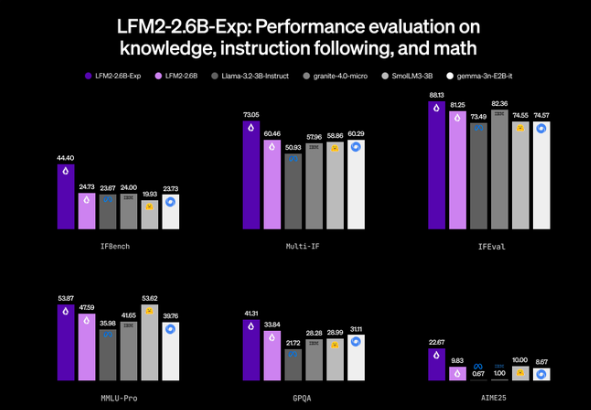
圣诞节当天,知名边缘AI初创公司Liquid AI正式发布了其最新实验性模型LFM2-2.6B-Exp,这一仅有2.6B(26亿)参数的小型开源模型,在多项关键基准测试中表现出色,尤其在指令跟随能
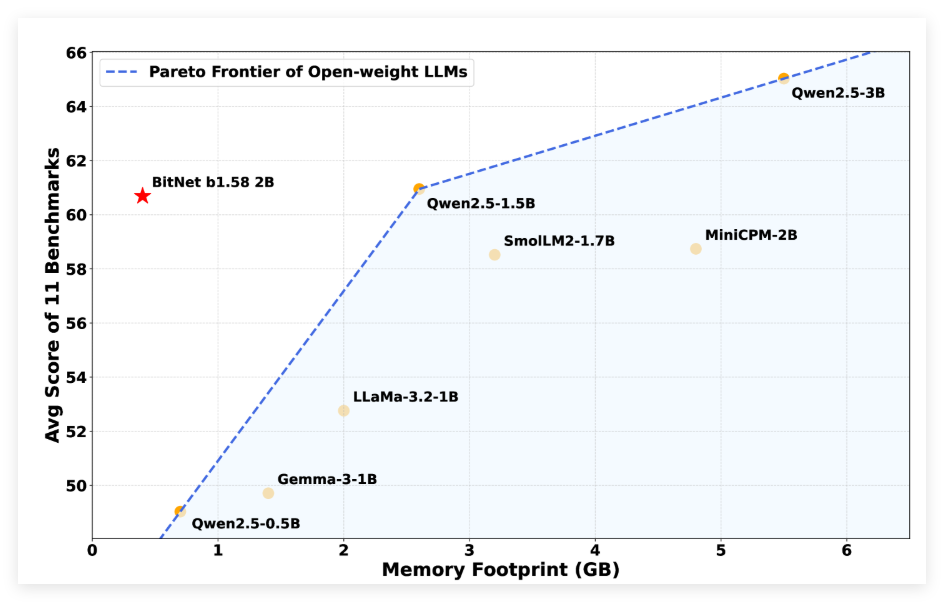
先日、マイクロソフトの研究チームは、BitNet b1.582B4Tというオープンソースの大規模言語モデルを発表しました。このモデルは20億のパラメータを持ち、独自の1.58ビット低精度アーキテク
近日,微软研究团队正式发布了一款名为 BitNet b1.582B4T 的开源大型语言模型。这款模型拥有20亿参数,采用了独特的1.58位低精度架构进行原生训练,与传统的训练后量化方式相比,Bit
近日,微軟研究團隊正式發佈了一款名爲 BitNet b1.582B4T 的開源大型語言模型。這款模型擁有20億參數,採用了獨特的1.58位低精度架構進行原生訓練,與傳統的訓練後量化方式相比,Bit

【研究の転換点】 清華大学と上海交通大学が共同発表した最新の論文は、業界で広く信じられている「純粋な強化学習(RL)は大規模言語モデルの推論能力を向上させる」という見解に異議を唱えています。研
【研究顛覆】 清華大學與上海交通大學聯合發表的最新論文,對業界普遍認爲"純強化學習(RL)能提升大模型推理能力"的觀點提出了挑戰性反駁。研究發現,引入強化學習的模型在某些任務中的表現,反而遜色於
【Research Upends Conventional Wisdom】 A recent joint paper from Tsinghua University and Shanghai


