

谷歌在 5 月 19 日正式发布了其最新的 Gemini Omni 模型,标志着其在人工智能领域的一次重大突破。作为 Gemini 模型家族的最新成员,Gemini Omni 将多模态技术提升到了

谷歌近日发布原生多模态嵌入模型 Gemini Embedding2,该模型可将文本、图像、视频、音频以及 PDF 文档统一映射到同一语义向量空间,旨在简化复杂的 AI 数据处理流程,并提升多模态检
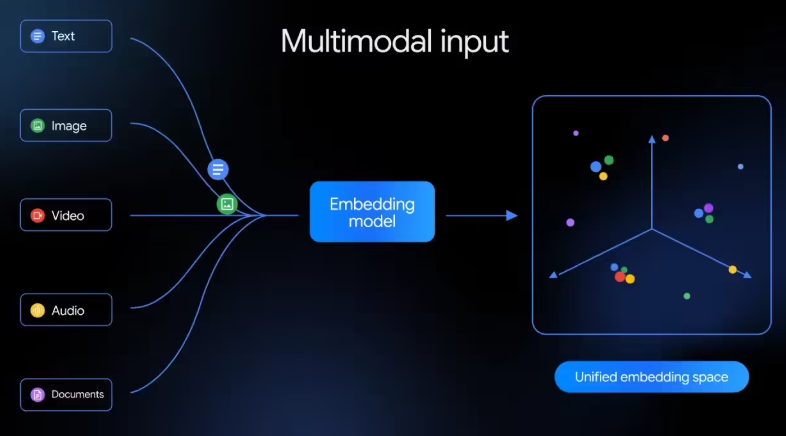
谷歌正式推出全新 Gemini Embedding2模型。作为谷歌首个原生多模态嵌入模型,它打破了传统模型仅支持单一数据类型的局限,能够将文本、图像、视频、音频和文档同时映射到同一个数学向量空间中
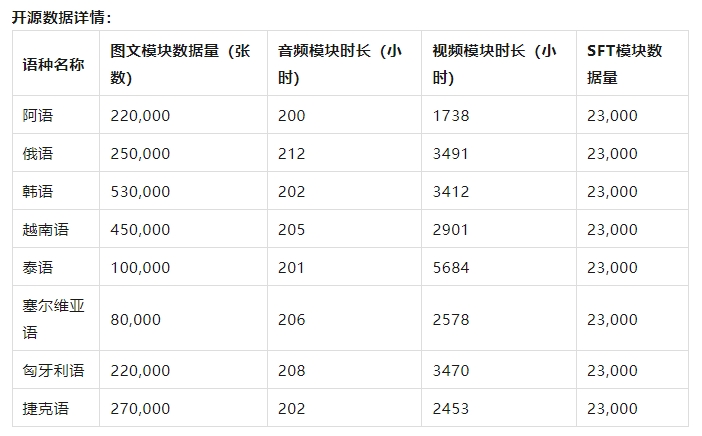
上海人工知能研究所が公開した「万巻・シルクロード2.0」多言語多モーダル語料庫が正式にオープンソース化されました。この語料庫は、既存のアラビア語、ロシア語、韓国語、ベトナム語、タイ語の5言語に加え

在过去的两年里,人工智能领域的关注点逐渐转向了大模型的技术发展,而商汤科技作为一家成立不到十年的公司,凭借其在计算机视觉领域的技术积累,正迅速转型,迎接这一浪潮。尽管在2023年之前,商汤主要聚焦
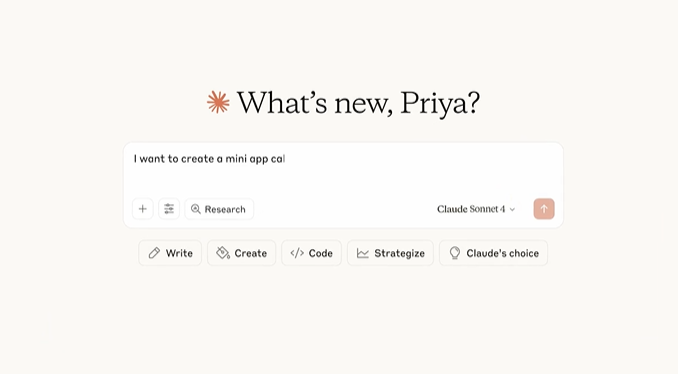
近日,AI技术领域迎来一项重要更新。Claude artifacts(Claude神器)功能得到了进一步增强, пользователи(用户)如今可以上传PDF、图像、代码文件等多种格式的数据,
近日,AI技術領域迎來一項重要更新。Claude artifacts(Claude神器)功能得到了進一步增強, пользователи(用戶)如今可以上傳PDF、圖像、代碼文件等多種格式的數據,
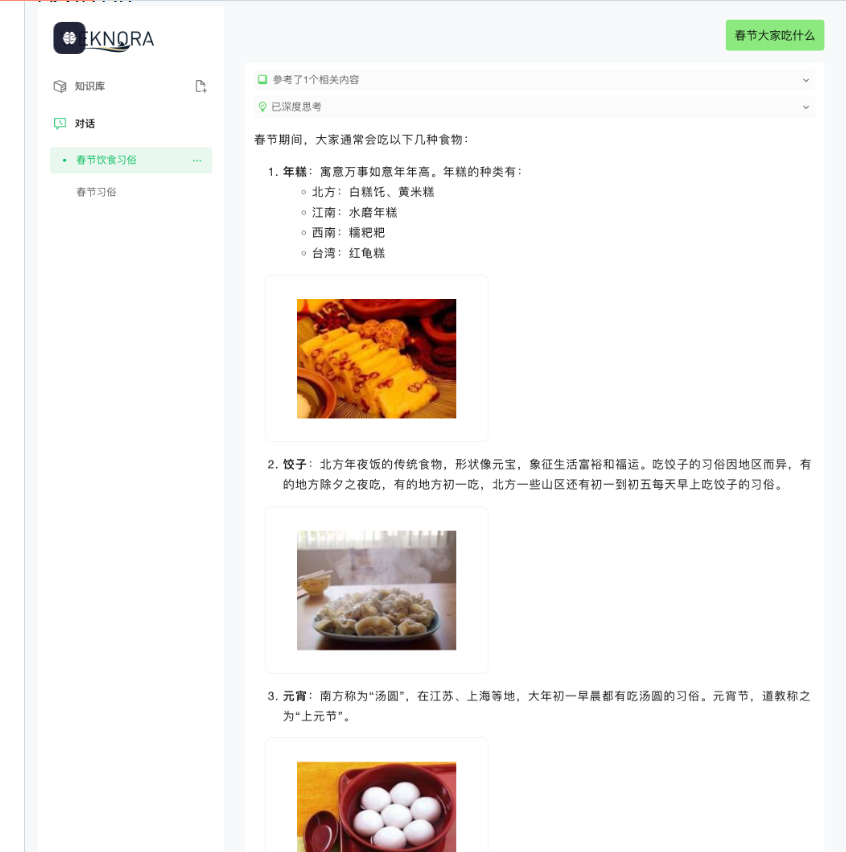
In the era of information explosion, processing complex documents has always been a challenge for
谷歌最近在其 Google I/O 活動上宣佈了一款名爲 SynthID Detector 的新工具,旨在幫助用戶檢查內容是否由其 AI 工具生成。 谷歌 DeepMind 的 Pushmeet

近日,谷歌正式發佈了開源框架 LMEval,旨在爲大語言模型(LLM)和多模態模型提供標準化的評測工具。這一框架的推出,不僅簡化了跨平臺模型性能比較,還支持文本、圖像和代碼等多領域的評估,展現了谷


