

A new Gartner report predicts that by 2027, businesses will use task-specific AI models three time

ByteDance has announced the launch of Efficient Pretraining Length Scaling, leveraging a novel Par

On April 24th, a blockchain virtual machine named DTVM (Deterministic Virtual Machine) was announc

現在的大模型(LLMs)已經非常智能。寫文章、編代碼、當醫生、當老師,樣樣精通。於是乎,有人就想了:既然它們這麼聰明,能不能讓它們自己做決定,當個“智能體”呢?比如,在複雜的環境裏自己探索、自己解
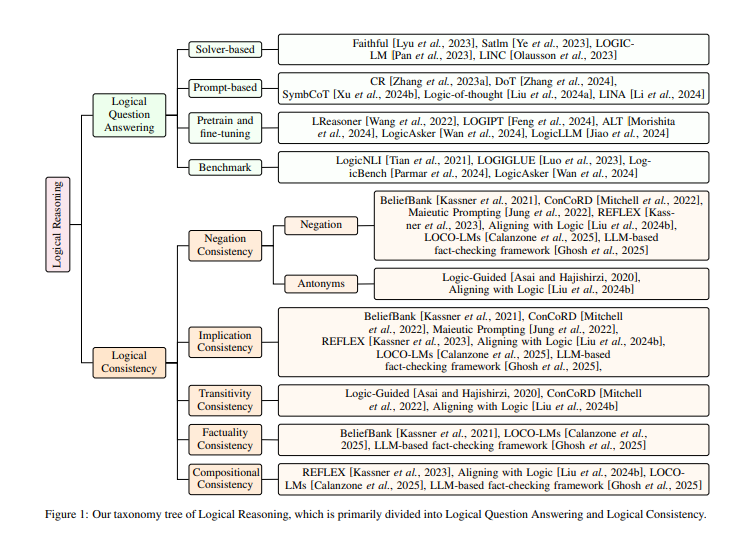
在當前人工智能領域,大語言模型(LLMs)取得了顯著成就,但其邏輯推理能力依然顯得不足。爲了提升這一能力,來自北京大學、清華大學、阿姆斯特丹大學、卡內基梅隆大學以及阿布扎比的 MBZUAI 等五所
在当前人工智能领域,大语言模型(LLMs)取得了显著成就,但其逻辑推理能力依然显得不足。为了提升这一能力,来自北京大学、清华大学、阿姆斯特丹大学、卡内基梅隆大学以及阿布扎比的 MBZUAI 等五所

The emergence of the Model Context Protocol (MCP) heralds a fundamental transformation in the ecos

Google has officially released a new open-source Python library LangExtract, designed to efficient
近日,OpenAI 發佈了一款名爲 HealthBench 的開源評估框架,旨在測量大型語言模型(LLMs)在真實醫療場景中的表現和安全性。此框架的開發得到了來自60個國家和26個醫學專業的262

この記事の公開URLは次のとおりです: (https://arxiv.org/pdf/2505.09343) この研究では、大規模言語モデル(LLMs)の急速な拡張が既存のハードウェアアーキテク


