登录之后可以开启更多功能哦
研究机构 METR 最新发布的一项研究显示,被广泛用于评估 AI 编程能力的基准测试 SWE-bench Verified 可能显著高估了 AI 代理在真实软件开发环境中的表现。研究发现,在基准测
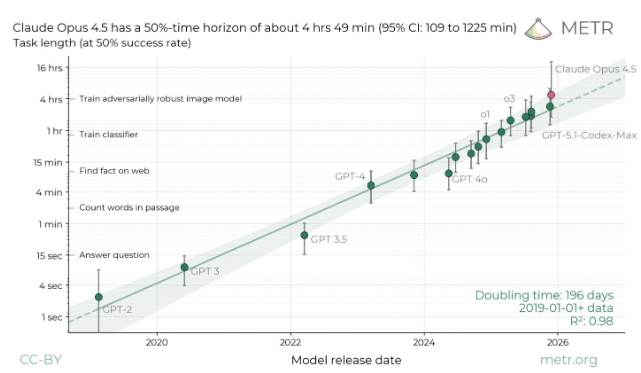
在追求大模型“高智商”的同时,AI 的持续执行能力正成为衡量其进化水平的新维度。根据人工智能研究机构 METR 发布的最新基准测试,Anthropic 旗下的顶级
OpenAI 近期推出了一项新系统,旨在监控其最新的 AI 推理模型 o3和 o4-mini,以阻止与生物和化学威胁相关的提示。该系统的目标是防止模型提供可能教唆他人实施有害攻击的建议,确保 AI