
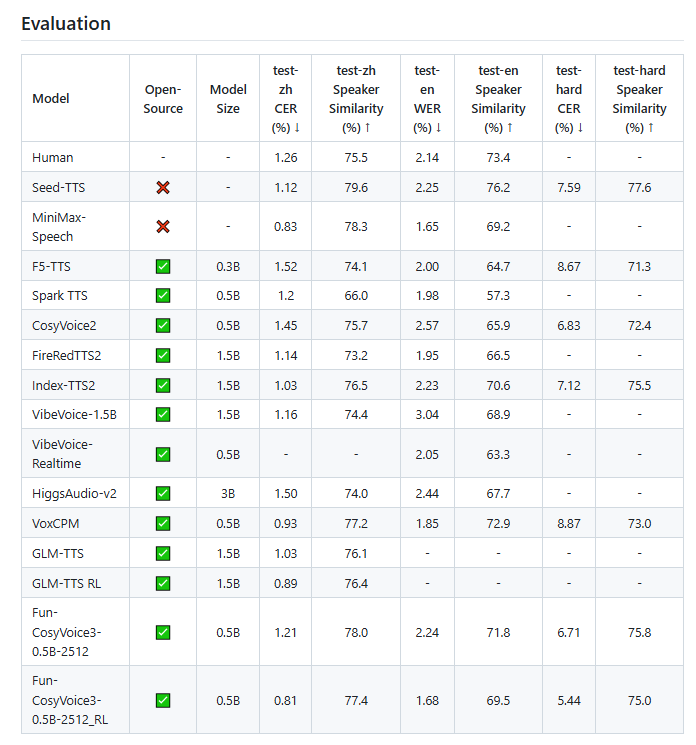
阿里巴巴通义大模型宣布,其 “百聆” 系列语音模型迎来了重大升级,并正式开源。此次更新的两款语音模型,能够在仅需三秒的录音后,实现无缝切换至多达九种语言和十八种方言,包括普通话、粤语、日语、英语等

在近期于圣地亚哥举行的 NeurIPS 大会上,英伟达推出了其最新的自动驾驶 AI 模型 Alpamayo-R1(AR1),旨在加速实现更广泛的无人驾驶汽车。英伟达称,AR1是全球首个用于自动驾驶
在AI浪潮席卷全球的当下,云计算巨头Cloudflare再度出手,推出了一款颠覆性开源工具——VibeSDK。这款平台被誉为“AI版Google AI Studio的Cloudflare升级版”,

微软公司宣布将在未来两年内,在加拿大再投资 54 亿美元,以提升该国的数字及人工智能基础设施。这项投资使得微软在 2023 至 2027 年间在加拿大的总支出达到 137 亿美元。根据微软的计划,

近日,美团 LongCat 团队宣布推出 LongCat-Image 图像生成模型,并将其开源。这一新模型以6B 参数规模实现了高性能与低门槛的完美结合,旨在满足当前日益增长的 AI 图像生成需求

苹果公司正式发布了其全新的视频生成模型 STARFlow-V,该模型在底层技术上与当前主流的Sora、Veo和Runway等竞争对手完全不同。STARFlow-V 放弃了业界主流的扩散模型(Dif
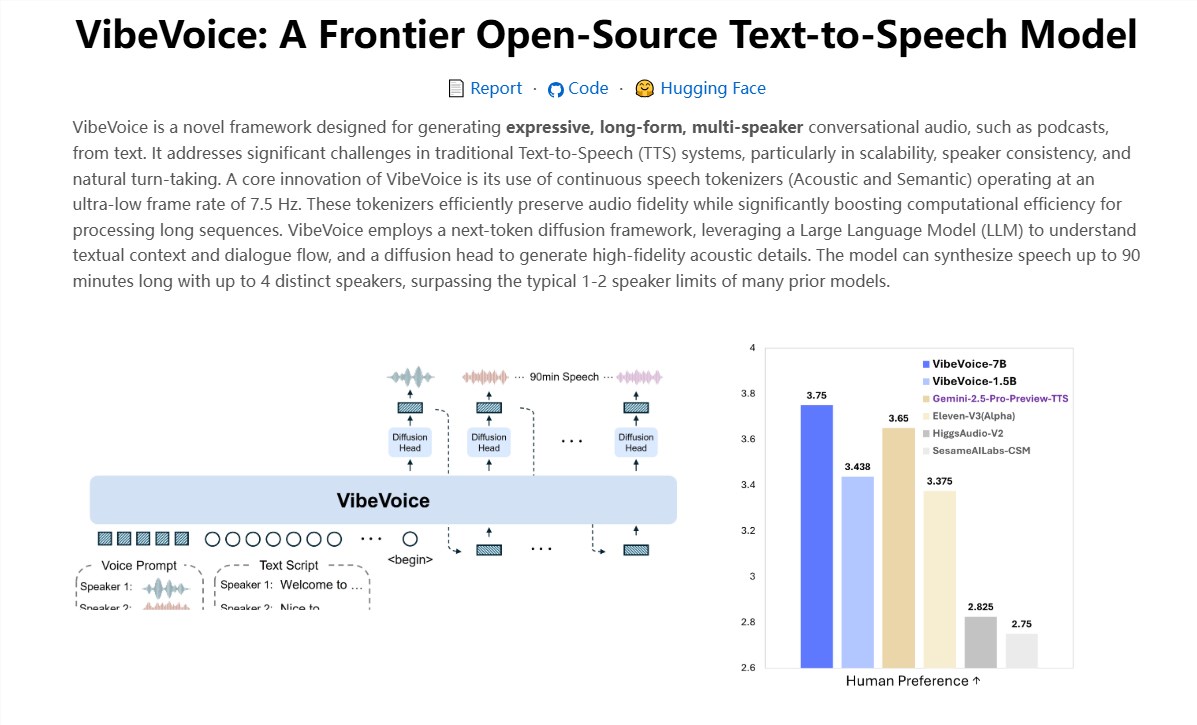
微软悄然开源了一枚“黑马级”实时语音模型:VibeVoice-Realtime-0.5B。这可能是目前全球延迟最低、表现最接近真人的开源文本转语音(TTS)模型之一,话还没说完,声音就已经开始了!
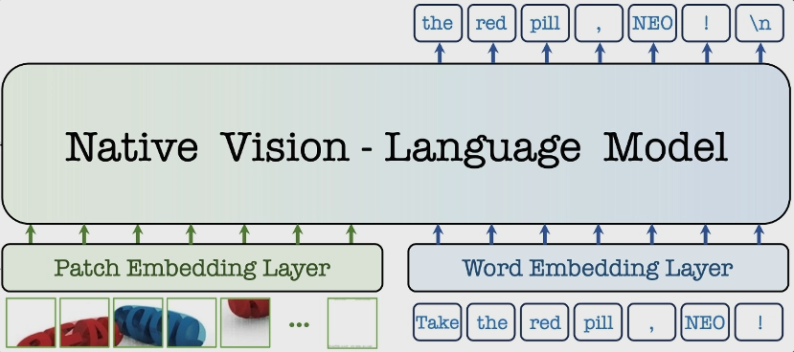
商汤科技联合南洋理工大学 S-Lab 发布行业首个原生多模态架构 NEO,并同步开源2B 与9B 两款模型。新架构摒弃“视觉编码器 + 投影器 + 语言模型”的传统三段式方案,从注意力机制、位置编

法国独角兽 Mistral AI 于12月2日推出 Mistral3系列模型,包括3B、8B、14B 三个小型密集模型及迄今最强的 Mistral Large3,覆盖从边缘设备到企业级推理的全场景
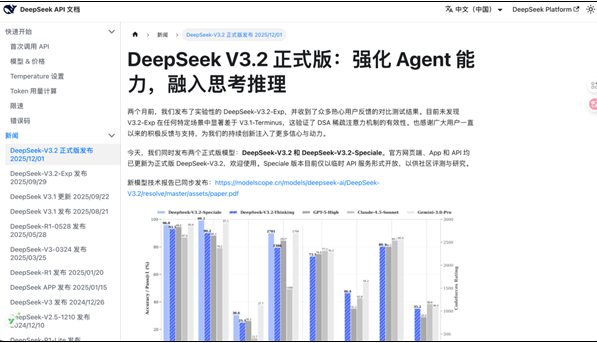
DeepSeek 发布 V3.2(标准版)与 V3.2-Speciale(深度思考版),官方评测显示: - V3.2在128k 上下文场景下与 GPT-5互有胜负 - V3.2-Special


