
阿里通义实验室的 Qwen Pilot 团队近日推出了一种全新的算法 FIPO(Future-KL Influenced Policy Optimization),该算法旨在突破当前大模型在推理过

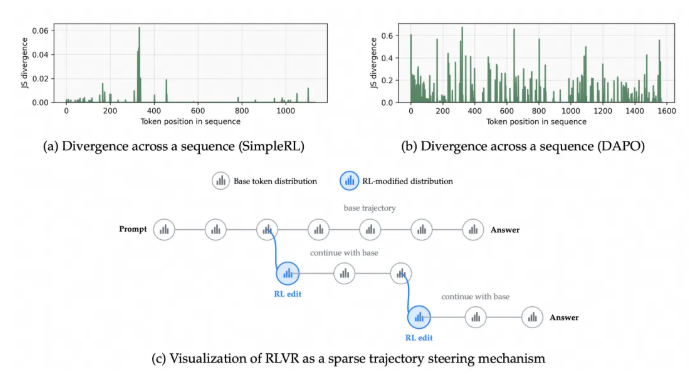
【研究の転換点】 清華大学と上海交通大学が共同発表した最新の論文は、業界で広く信じられている「純粋な強化学習(RL)は大規模言語モデルの推論能力を向上させる」という見解に異議を唱えています。研
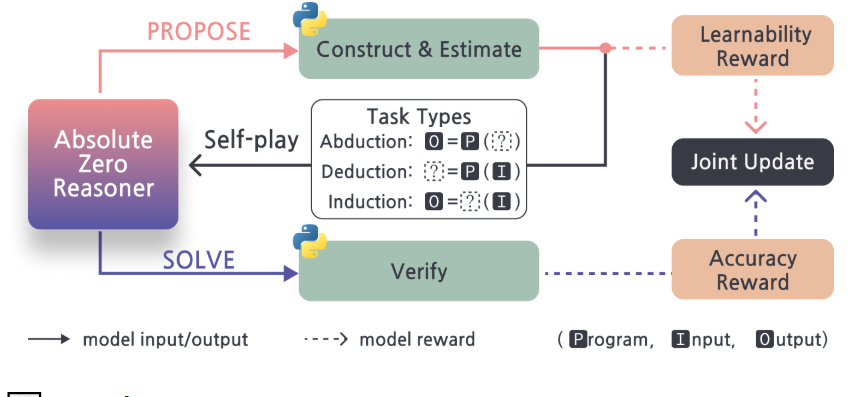
一項名爲Absolute Zero Reasoner(AZR)的創新項目近日引發廣泛關注。該項目通過一種全新的“絕對零點”訓練範式,讓大型語言模型(LLM)能夠自主提出問題、編寫代碼、運行驗證,並
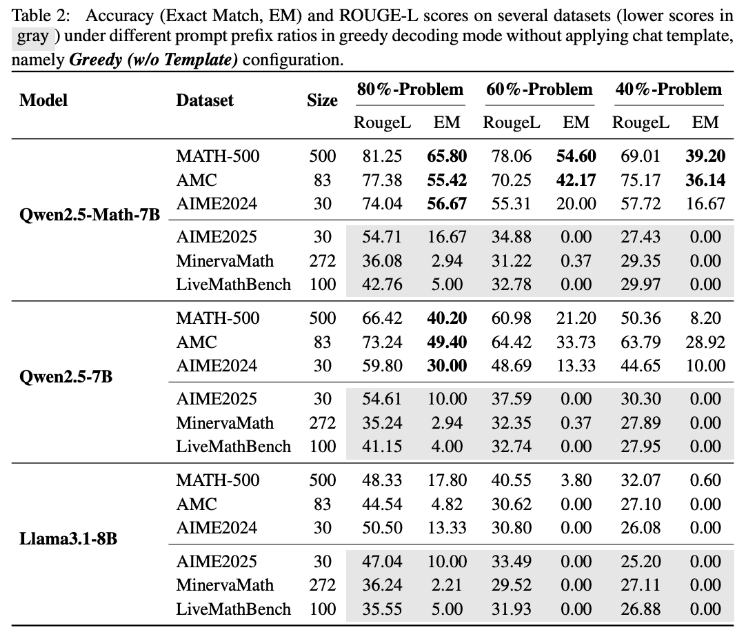
国外メディアの報道によると、最新の研究ではアリババのQwen2.5モデルが得た高い数学スコアに疑問を投げかけており、その見かけ上の優れた数学的推論能力が、実際に推論によるものではなく、訓練データへ
据国外媒体报道, 一项最新研究对阿里巴巴Qwen2.5模型的高数学分数提出了质疑,指出其看似卓越的数学推理能力,可能主要来源于对训练数据的记忆,而非真正的推理。研究人员通过一系列严谨的测试发现,数


